

728x90

데이터 분석 복습
1. 데이터 분석 방법론
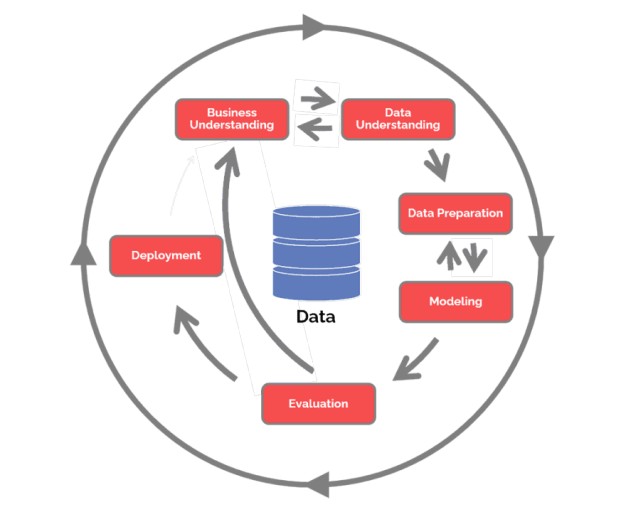
CRISP-DM(Cross-Industry Standard Process for Data Mining)
1) 비즈니스 이해(Business Understanding)
- 문제를 정의하고 요인을 파악하기 위한 가설 수립
- 비즈니스 이해하는 단계
- 업무 목적 파악, 데이터 마이닝 목표 설정, 프로젝트 계획 수립
2) 데이터 이해(Data Understanding)
- 데이터 수집 및 속성 이해
- 초기 데이터 수집, 데이터 기술 분석, 데이터 탐색, 데이터 품질 확인
데이터 분석 도구
- EDA(Exploratory Data Analysis)
- 개별 데이터의 분포, 가설이 맞는지 파악
- NA, 이상치 파악
- CDA(Confirmatory Data Analysis)
- 탐색으로 파악하기 애매한 정보는 통계적 분석 도구(가설 검정) 사용
3) 데이터 준비(Data Preparation)
- 데이터를 분석 가능한 상태로 만드는 단계
- 모델링을 위한 데이터 구조 만들기
수행되는 내용
- 결측치 처리(삭제, 채우기)
- 가변수화(범주의 숫자화)
- 스케일링
- 데이터 분할
4) Modeling
- 다양한 모델링 기법과 알고리즘을 선택하고 매개변수를 최적화
- 데이터로부터 패턴을 찾는 과정
5) 평가(Evaluation)
- 모델이 프로젝트 목표에 부합하는지 평가, 결과의 수용 여부 판단
- 비즈니스 기대가치 평
6) 전개, 배포(Deployment)
- 프로덕션 환경의 파이프라인, 모델 및 배포가 고객 목표를 충족하는지 확인
- 전개 계획 수립, 모니터링과 유지보수 계획수립, 프로젝트 종료 보고서 작성, 프로젝트 리뷰
2. 분석을 위한 데이터 구조와 EDA & CDA
분석(모델링)할 수 있는 정보(데이터)의 종류
1) 범주형
- 질적(정성적 데이터)
- 명목형 데이터: ex) 성별, 주소지, 흡연여부
- 순서형 데이터: ex) 연령대, 고객등급
2) 수치형
- 양적(정량적 데이터)
- 이산형 데이터: ex) 통화량, 소득수준, 가입기간, 나이
- 연속형 데이터: ex) 온도, 몸무
분석하기 위한 데이터의 구조
- x: feature → 요인, input, 독립변수
- y: target → 결과, output, 종속변수, Label
EDA (탐색적 데이터 분석 - Exploratory Data Analysis)
&
CDA (확증적 데이터 분석 - Confirmatory Data Analysis)
EDA 및 CDA의 순서
- 단변량 분석: 개별 변수의 분포
- ex) 타이타닉 탑승객의 나이 분석
- 이변량 분석1: feature와 target 간의 관계 (가설을 확인하는 단계)
- ex) 객실등급 → 생존여부 (객실등급에 따라 생존여부에 차이가 있나?)
- 이변량 분석2: feature들 간의 관계
3. 시각화 라이브러리
기본 세팅
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%config InlineBackend.figure_format = 'retina' # 화질개선
plt.rcParams['font.family'] = 'Malgun Gothic' # 한글 폰트 사용
plt.rcParams['axes.unicode_minus'] = False # 한글 폰트 사용 시, 마이너스 글자가 깨지는 현상해결
차트 그리기
plt.plot(data['Date'], data['Ozone']
,color='green' # 칼러
, linestyle='dotted' # 라인스타일
, marker='o') # 값 마커(모양)
plt.xlabel('Date') # x축 이름 지정
plt.ylabel('Ozone') # y축 이름 지정
plt.title('Daily Airquality') # 타이틀
plt.xticks(rotation=45) # x축 값 꾸미기 : 방향을 45도 틀어서
plt.show()
더 많은 스타일은 Matplotlib의 공식 웹사이트(https://matplotlib.org/)
범례, 그리드 추가
plt.plot(data['Date'], data['Ozone'], label = 'Ozone') # label = : 범례추가를 위한 레이블값
plt.plot(data['Date'], data['Temp'], label = 'Temp')
plt.legend(loc = 'upper right') # 레이블 표시하기. loc = : 위치
plt.grid()
plt.xticks(rotation=45)
plt.show()loc = best, upper right, upper left, lower left
추가 기능 1
plt.plot(data['Ozone'])
# y축의 범위를 0부터 100까지로 설정
plt.ylim(0, 100)
# x축의 범위를 0부터 10까지로 설정
plt.xlim(0, 10)
# y축에서 값이 40인 위치에 회색 점선 추가
plt.axhline(40, color='grey', linestyle='--')
# x축에서 값이 10인 위치에 빨간색 점선 추가
plt.axvline(10, color='red', linestyle='--')
# (5, 41) 위치에 '40'이라는 텍스트 추가
plt.text(5, 41, '40')
# (10.1, 20) 위치에 '10'이라는 텍스트 추가
plt.text(10.1, 20, '10')
plt.show()
추가 기능 2: 여러 그래프 나눠서 그리기
# 형식
plt.subplot(row, column, index)- row : 고정된 행 수
- column : 고정된 열 수
- index : 순서
plt.figure(figsize = (12,8))
plt.subplot(3,1,1)
plt.plot('Date', 'Temp', data = data)
plt.grid()
plt.subplot(3,1,2)
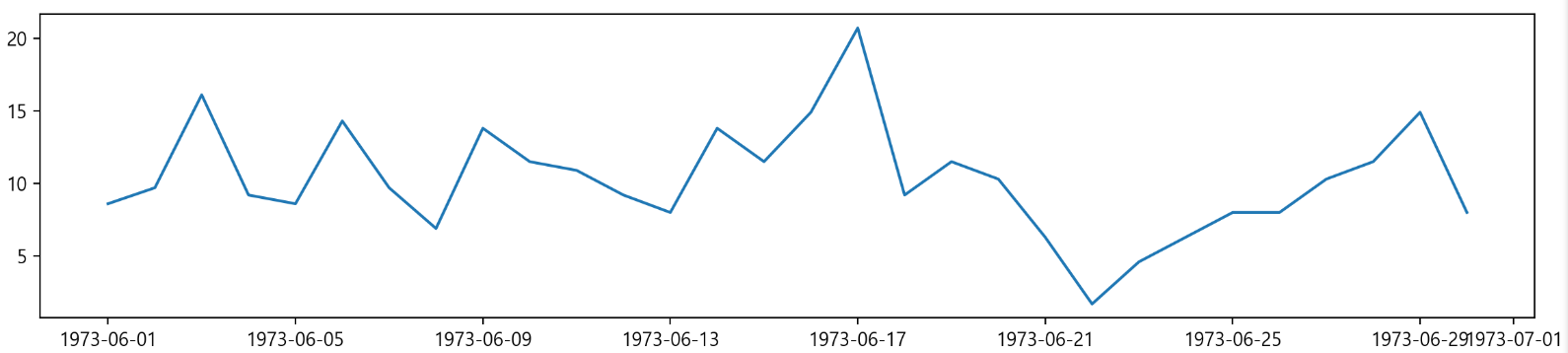
plt.plot('Date', 'Wind', data = data)
plt.subplot(3,1,3)
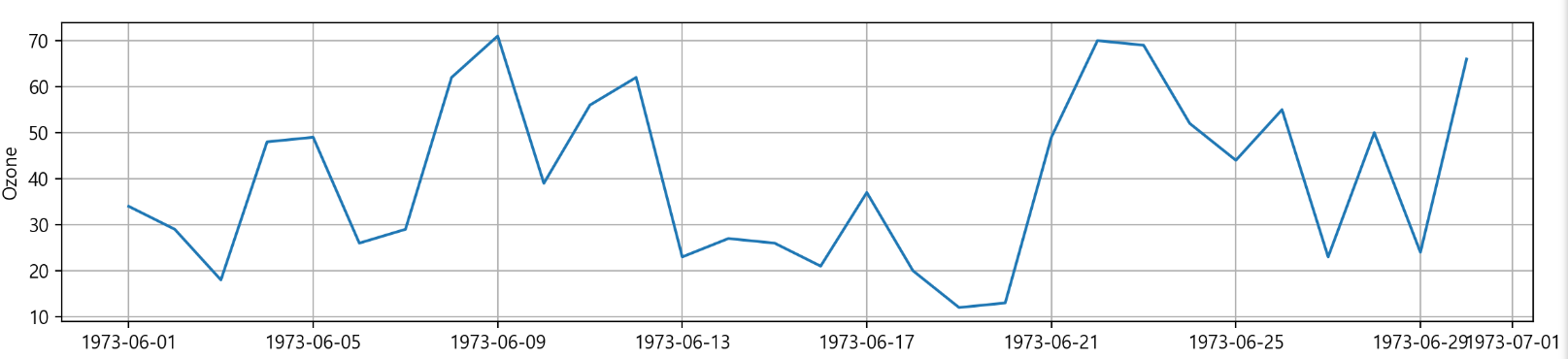
plt.plot('Date', 'Ozone', data = data)
plt.grid()
plt.ylabel('Ozone')
plt.tight_layout() # 그래프간 간격을 적절히 맞추기
plt.show()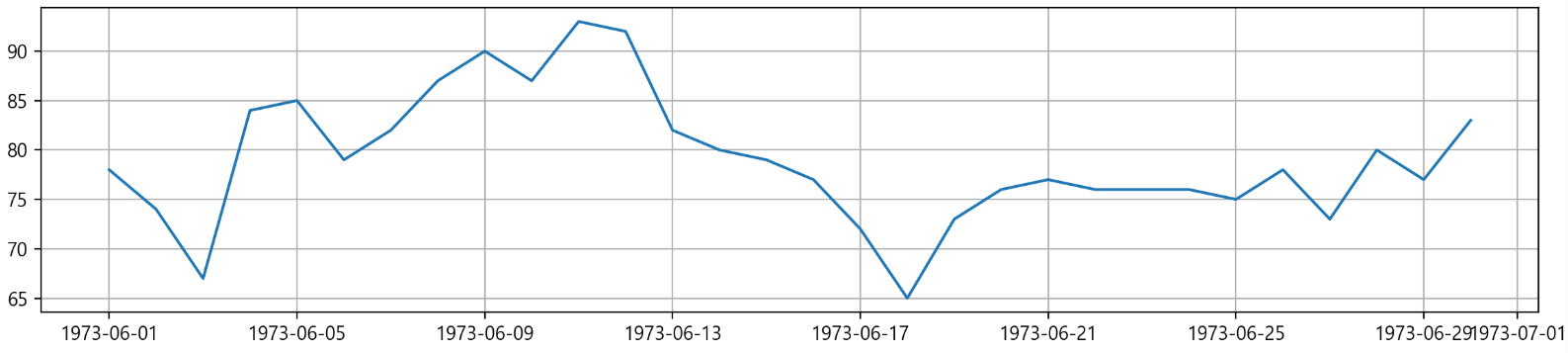
4. 개별 변수 분석(단변량 분석) 숫자형 변수
숫자형 변수를 정리하는 방법
1) 숫자로 요약하기: 정보의 대푯값
- 기초 통계량
- 평균(mean), 중앙값(median), 최빈값(mode), 사분위수(Quantile)
2) 구간을 나누고 빈도수(frequency) 계산
- 도수분포표
숫자형 변수 시각화하기
Histogram
plt.subplot(2,2,1)
sns.histplot(x = 'Age',data = titanic, bins = 8)
plt.subplot(2,2,2)
sns.histplot(x = 'Age',data = titanic, bins = 16)
plt.subplot(2,2,3)
sns.histplot(x = 'Age',data = titanic, bins = 32)
plt.subplot(2,2,4)
sns.histplot(x = 'Age',data = titanic, bins = 64)
plt.tight_layout() # 그래프간 간격을 적절히 맞추기
plt.show()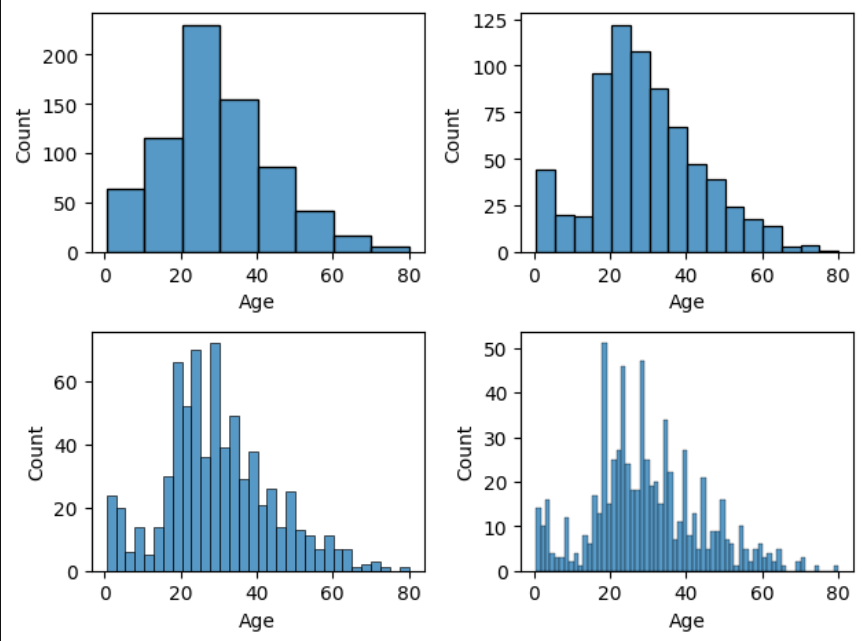
그래프 읽기
- 축의 의미 파악(x축, y축)
- 값의 분포 파악(희박 구간, 밀집 구간)
- 이에 대한 비즈니스 의미 파악
- 해당 구간의 비즈니스 원인을 파악
- 추가적인 분석 대상 설정
커널 밀도 추정 (Kernel Density Estimation, KDE)
- 히스토그램은 구간(bin)의 너비(개수)를 어떻게 잡는지에 따라 전혀 다른 모양이 될 수 있다는 단점 존재
- 구간의 너비를 정하지 않아도 됨
- 데이터의 밀도 추정
Boxplot
- 반드시 Nan 제외(seaborn에서는 자동 제외)
- vert 옵션(vertical)으로 횡(False), 종(True, 기본값)으로 그릴 수 있음
temp = titanic.loc[titanic['Age'].notnull()]
plt.boxplot(temp['Age'], vert = False)
plt.grid()
plt.show()
박스: 4분위수
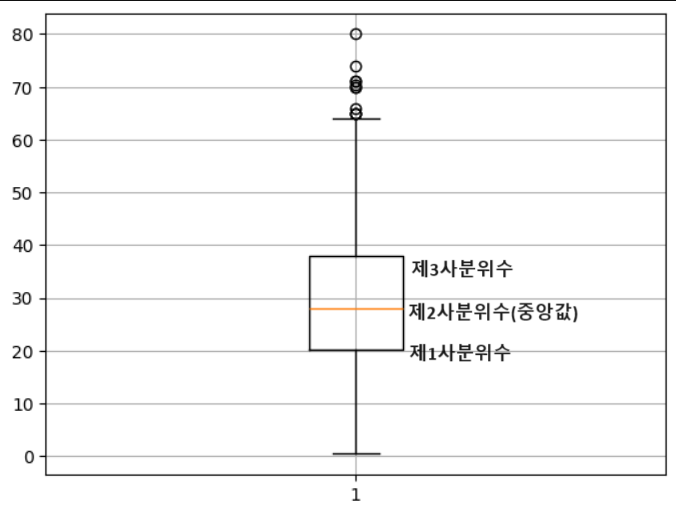
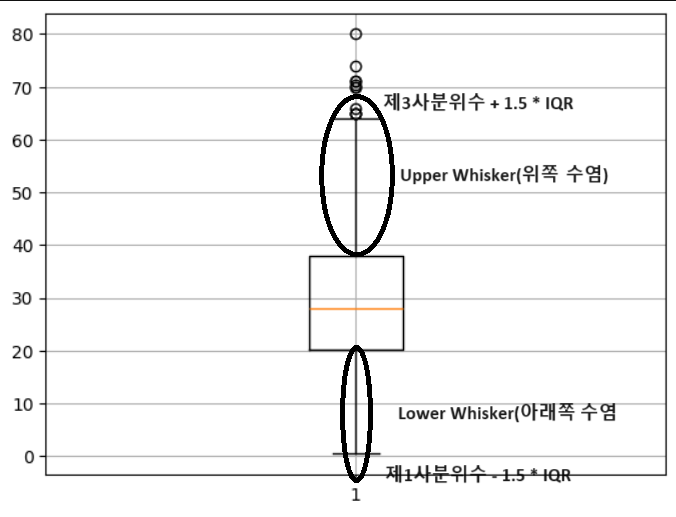
IQR
- 3사분위수 - 1사분위수
- Actual Whisker Length : 1.5*IQR 범위 이내의 최소, 최대값으로 결정
- Potential Whisker Length : 1.5*IQR 범위, 잠재적 수염의 길이 범위
5. 개별 변수 분석(단변량 분석) 범주형 변수
- 자연 발생적 data가 아니라, 우리가 정해주는 것
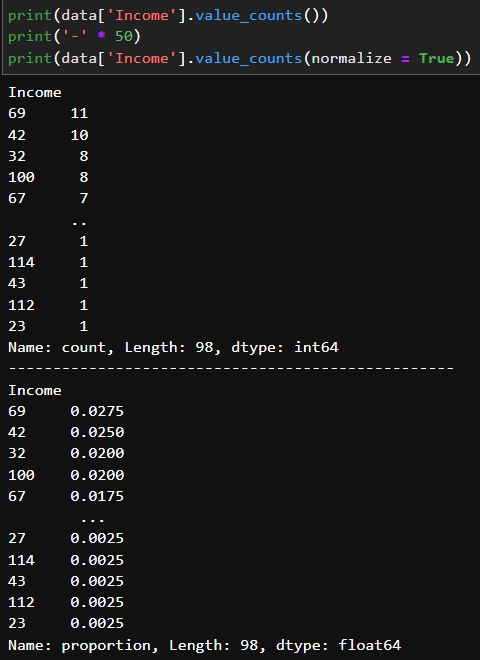
범주별 빈도수
- 시리즈.value_counts()
범주별 비율
- 시리즈.value_counts(normalize = True)
범주형 변수 시각화
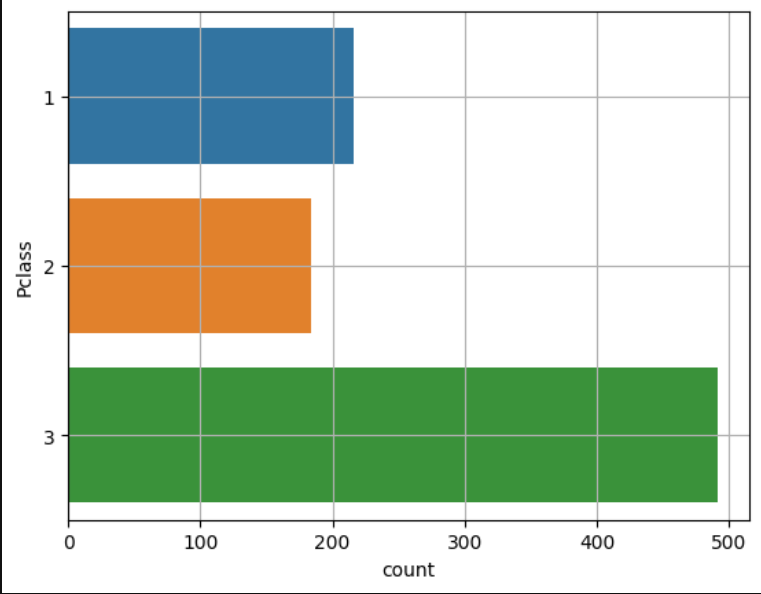
sns.countplot
- 범주별 빈도수가 알아서 계산
sns.countplot(x=titanic['Pclass'])
sns.countplot(x='Pclass', data=titanic)
sns.countplot(y='Pclass', data=titanic) # 가로로 표시
plt.grid()
plt.show()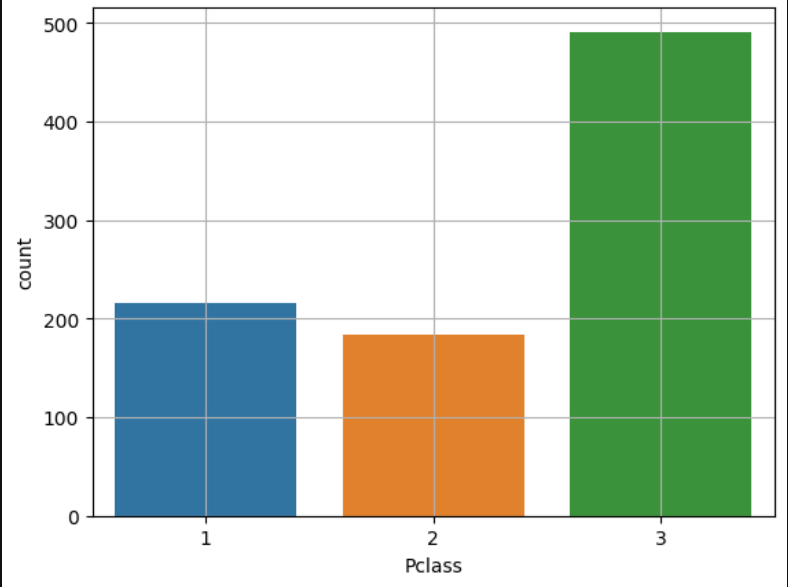
| 기초통계량 | 그래프 | |
| 수치형 | min, max, mean, std, 사분위수 | 히스토그램, kde. box plot |
| 범주형 | 범주별 빈도수, 범주별 비율 | 막대 그래프(sns.countplot) |
728x90
'KT AIVLE > DX 복습' 카테고리의 다른 글
| [KT AIVLE] DX트랙 데이터 수집(5주차) 복습(웹 크롤링, json, HTML, CSS) (2) | 2024.03.20 |
|---|---|
| [KT AIVLE] DX트랙 데이터 분석(4주차) 복습(가설검정, 이변량분석, T-Test, ANOVA, 카이제곱검정 ) (4) | 2024.03.16 |
| [KT AIVLE] DX트랙 데이터 다듬기(3주차) 복습(판다스 데이터프레임 변경) (0) | 2024.03.10 |
| [KT AIVLE] DX트랙 데이터 다듬기(2~3주차) 복습(넘파이 연산, 판다스 데이터프레임 함수, 조회, 집계) (0) | 2024.03.10 |
| [KT AIVLE] KT 에이블스쿨 5기 DX트랙 데이터 다루기(1~2주차) 복습 (1) | 2024.03.06 |