

728x90

머신러닝 복습
머신러닝
1. 머신러닝
- 컴퓨터 시스템에게 데이터에서 학습하고 패턴을 식별하여 작업을 수행할 수 있는 능력을 부여하는 인공지능의 한 분야
- 다양한 알고리즘과 기술을 사용하여 모델을 훈련시키고, 이 모델은 새로운 데이터를 분석하고 예측하거나 패턴을 인식하여 의사 결정을 내림
지도학습(Supervised Learning)
- 학습 대상이 되는 데이터에 정답을 주어 규칙성을 배우게 하는 방법
비지도학습(Unsupervised Learning)
- 정답이 없는 데이터만으로 배우게 하는 학습 방법
강화학습(Reinforcement Learning)
- 선택한 결과에 대해 보상을 받아 행동을 개선하면서 배우게 하는 학습 방법
2. 분류와 회귀
분류
- 범줏값을 예측
- 로지스틱 회귀 (Logistic Regression), 결정 트리 (Decision Trees), 랜덤 포레스트 (Random Forest), 서포트 벡터 머신 (Support Vector Machine, SVM), k-최근접 이웃 (k-Nearest Neighbors, k-NN) 등
회귀
- 연속적인 숫자를 예측
- 두 값 사이의 중간값이 의미가 있는 숫자인지
- 두 값에 대한 연산 결과가 의미가 있는 숫자인지
- 선형 회귀 (Linear Regression), 다항 회귀 (Polynomial Regression), 결정 트리 회귀 (Decision Tree Regression), 랜덤 포레스트 회귀 (Random Forest Regression)
분류와 회귀는 서로 다른 함수를 사용해서 모델링을 함
- 문제 유형 파악
- 알고리즘, 평가 방법 선택
- 적합한 함수를 사용해 모델링
3. 관련 용어
모델
- 데이터로부터 패턴을 찾아 수학식으로 정리해 놓은 것
모델링
- 오차가 적은 모델을 만드는 과정
모델의 목적
- 샘플을 가지고 전체를 추정
- 샘플: 표본, 부분집합, 일부, 과거의 데이터
- 전체: 모집단, 전체집합, 현재와 미래의 데이터
- 추정: 예측, 추론
독립변수
- Features, 원인, x
종속변수
- Target, 결과, y
오차
- 관측값(=실젯값)과 모델 예측값의 차이: 이탈도(Deviance)
데이터 셋을 학습용(Training), 검증용(Validation), 평가용(Testing) 데이터로 분리 함
과대적합(Overfitting)
- 모델이 학습 데이터에 너무 맞춰져서 새로운 데이터에 대한 일반화 성능이 떨어지는 현상
- 학습 데이터에 대해서만 잘 맞는 모델 - 실전에서 예측 성능이 좋지 않음
과소적합(Underfitting)
- 모델이 너무 단순하여 학습 데이터에 적합하지 않는 현상
- 모델이 학습 데이터의 패턴을 충분히 학습하지 못하여 학습 데이터와 새로운 데이터 모두에 대해 성능이 낮을 수 있음
4. 모델링 코드 구조
Scikit-Learn
# 학습용, 평가용 데이터 분리
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, r2_score# 1단계: 불러오기
# 회귀일 때
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error
# 분류일 때
# from sklearn.neighbors import KNeighborsClassifier
# from sklearn.metrics import accuracy_score
# 2단계: 선언하기
model = LinearRegression()
# 3단계: 학습하기
model.fit(x_train, y_train)
# 4단계: 예측하기
y_pred = model.predict(x_test)
# 5단계: 평가하기
print(mean_absolute_error(y_test, y_pred))
# print(accuracy_score(y_test, y_pred))
# 베이스라인
y_base = [y_train.mode()[0]] * len(y_test)
print(accuracy_score(y_test, y_base))
성능 평가
1. 회귀 모델 성능 평가
회귀 모델 평가
- 0인지 1인지 예측
- 예측 값이 실제 값에 가까울 수록 좋은 모델
| y | 실젯값 | Target, 목표값 오차: 실젯값과 예측값의 차이(y - ŷ) |
| ŷ(y_hat) | 예측값 | 새롭게 예측한 값 평균값보다 얼마나 잘 예측했을지(오차를 얼마나 더 줄였는지 )궁금 |
| ȳ(y_bar) | 평균값 | 이미 존재하고 있는 평균으로 예측한 값 최소한 평균값 보다는 실젯값에 가까운 예측값을 원함 |
MSE (평균 제곱 오차)
- 예측값과 실제값 간의 차이(오차)를 제곱하여 평균화한 값
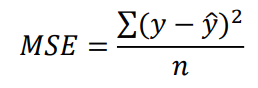
RMSE (평균 제곱근 오차)
- 예측값과 실제값 간의 차이에 대한 평균화된 오차의 제곱근
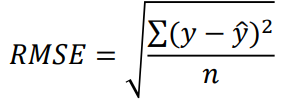
MAE (평균 절대 오차)
- 예측값과 실제값 간의 절대 차이의 평균
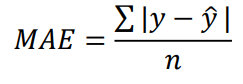
MAPE (평균 절대 백분율 오차)
- MAPE는 예측값과 실제값 간의 백분율 오차의 평균
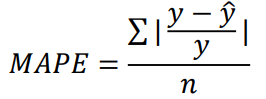
결정계수 (R-squared)
- Coefficient of Determination
- 전체 오차 중에서 회귀식이 잡아낸 오차 비율(일반적으로 0 ~ 1 사이)
- 일반적으로 높은 값이 더 좋은 모델을 나타냅니다.
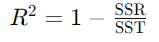
- SSR (Regression Sum of Squares): 전체 오차 중에서 회귀식이 잡아낸 오차
- SST (Total Sum of Squares): 전체 오차(최소한 평균 보다는 성능이 좋아야 하니, 우리에게 허용된(?) 오차)
MSE, RMSE, MAE, MAPE는 오류(Error) 이므로 작을 수록 좋고 R2 Score는 클 수록 좋음
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_absolute_percentage_error
from sklearn.metrics import r2_score
# 평가하기
# (실젯값, 예측값)
print('MSE:', mean_squared_error(y_test, y_pred))
print('MAE:', mean_absolute_error(y_test, y_pred))
print('RMSE:', mean_squared_error(y_test, y_pred, squared= False))
print('MAPE:', mean_absolute_percentage_error(y_test, y_pred))
print('R2:', r2_score(y_test, ypred))
2. 분류 모델 성능 평가
분류 모델 평가
- 예측 값이 실제 값과 많이 같을 수록 좋은 모델
Confusion Matrix(오분류표)
- TN(True Negative, 진음성): 음성으로 잘 예측한 것(음성을 음성이라고 예측한 것)
- FP(False Positive, 위양성): 양성으로 잘 못 예측한 것(음성을 양성이라고 예측한 것)
- FN(False Negative, 위음성): 음성으로 잘 못 예측한 것(양성을 음성이라고 예측한 것)
- TP(True Positive, 진양성): 양성으로 잘 예측한 것(양성을 양성이라고 예측한 것)

정확도(Accuracy, 정분류율)
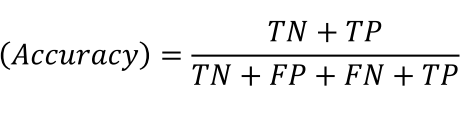
정밀도(Precision)
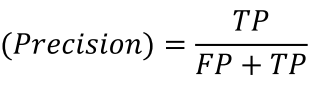
재현율(Recall, 민감도(Sensitivity))

특이도(Specificity)
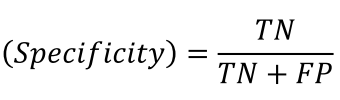
F1 - Score
- 정밀도, 재현율의 조화 평균
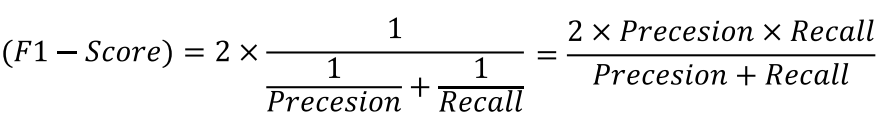
# 함수 불러오기
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
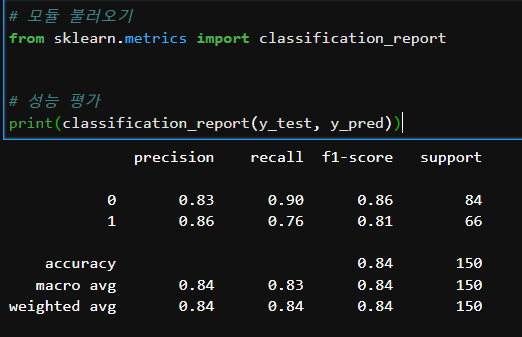
from sklearn.metrics import classification_report
# 평가하기
print(confusion_matrix(y_test, y_pred))
print('정확도:',accuracy_score(y_test,y_pred))
print('정밀도: ', precision_score(y_test, y_pred, average = None))
print('재현율: ', recall_score(y_test, y_pred, average = None))
한번에 평가!
728x90