

728x90

머신러닝 복습
기본 알고리즘
분류
- 범줏값을 예측
- 로지스틱 회귀 (Logistic Regression), 결정 트리 (Decision Trees), 랜덤 포레스트 (Random Forest), 서포트 벡터 머신 (Support Vector Machine, SVM), k-최근접 이웃 (k-Nearest Neighbors, k-NN) 등
회귀
- 연속적인 숫자를 예측
- 선형 회귀 (Linear Regression), 다항 회귀 (Polynomial Regression), 결정 트리 회귀 (Decision Tree Regression), 랜덤 포레스트 회귀 (Random Forest Regression)
1. Linear Regression(선형 회귀) 알고리즘
최선의 회귀모델은 전체 데이터의 오차합이 최소가 되는 모델을 의미
단순회귀(Simple Regression)
- 독립변수 하나가 종속변수에 영향을 미치는 선형회귀
- 모델학습 후 회귀계수 확인 가능
- coef_: 회귀계수(=가중치)
- intercept_: 편향
# 회귀계수확인
print(model.coef_)
print(model.intercept_)
다중회귀(Multiple Regression)
- 여러 독립변수가 종속변수에 영향을 미치는 선형회귀
- 𝑦값을 설명하기 위해서는여러 개의 𝑥값이 필요한 경우
# 회귀계수확인
print(list(x_train))
print(model.coef_)
print(model.intercept_)
Linear Regression 알고리즘으로 모델 구현
# 알고리즘 함수
from sklearn.linear_model import LinearRegression
# 성능평가 함수
from sklearn.metrics import mean_absolute_error, r2_score
# 선언하기
model = LinearRegression()
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print(mean_absolute_error(y_test, y_pred))
print(r2_score(y_test, y_pred))
2. K-Nearest Neighbor(k-최근접 이웃) 알고리즘
KNN
- k-Nearest Neighbor: k 최근접이웃(가장 가까운 이웃 k개)
- 학습용 데이터에서 k개의 최근접 이웃의 값을 찾아 그 값들로 새로운 값을 예측하는 알고리즘
- 회귀와 분류 모두 사용
K값의 중요성
- k 값에 따라 예측값이 달라지므로 적절한 k값을 찾는 것이 중요
거리 구하기
유클리드 거리(Euclidean Distance)
- 두 점 간의 직선 거리
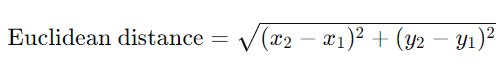
맨해튼 거리(Manhattan Distance)
- 두 점 간의 수직 및 수평 이동 거리
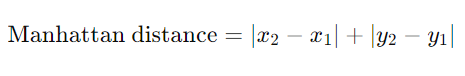
스케일링
- 데이터의 크기를 조정하는 과정
- 일반적으로는 특성(feature)의 크기를 조정하여 모델의 성능을 향상시키거나 최적화하는 데 사용
스케일링 방법 정규화
정규화(Normalization)
- 각 변수의 값이 0과 1사이 값이 됨
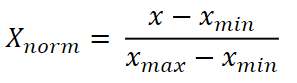
# 함수불러오기
from sklearn.preprocessing import MinMaxScaler
# 정규화
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train= scaler.transform(x_train)
x_test= scaler.transform(x_test)
KNN 알고리즘으로 모델 구현
# 알고리즘 함수
from sklearn.neighbors import KNeighborsRegressor
# 성능평가 함수
from sklearn.metrics import mean_absolute_error, r2_score
# 선언하기
model = KNeighborsRegressor()
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print(mean_absolute_error(y_test, y_pred))
print(r2_score(y_test, y_pred))
3. Decision Tree(결정 트리, 의사 결정 나무) 알고리즘
Decision Tree
- 분류와 회귀 모두에 사용되는 지도학습 알고리즘
- 화이트박스 모델: 분석 과정을 실제로 눈으로 확인 가능
- 의미 있는 질문을 먼저 하는 것이 중요
- 과적합(Overfitting)으로 모델 성능이 떨어지기 쉬움
- 트리 깊이를 제한하는 (=가지치기) 튜닝이 필요
Decision Tree 용어
- Root Node(뿌리마디): 전체 데이터를 가지고 있는 시작하는 마디, 모든 결정 트리의 가장 상위에 위치
- Child Node(자식마디): 한 마디로부터 분리된 두 개 이상의 마디
- Parent Node(부모마디): 주어진 마디의 상위 마디
- Terminal Node(끝마디): 자식 마디가 없는 마디(=Leaf Node), 결정 트리에서 최종적인 예측이 이루어지는 지점
- Internal Node(중간마디): 부모 마디와 자식 마디가 모두 있는 마디
- Branch(가지): 연결되어 있는 두 개 이상의 마디, Root Node부터 Leaf Node까지 연결된 경로를 가지라고 함
- Depth(깊이): Root Node로부터 Leaf Node까지 연결된 마디의 개수
불순도를 수치화 할 수 있는 지표: 지니 불순도, 엔트로피
지니 불순도
- 1 − (양성 클래스 비율의 제곱+음성 클래스 비율의 제곱)
- 지니 불순도는 0부터 1까지의 값을 가짐
- 값이 작을수록 노드의 혼잡도가 낮고(즉, 불순도가 낮음), 값이 클수록 혼잡도가 높음(즉, 불순도가 높음).
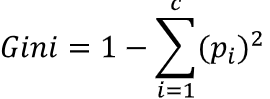
가지치기
- 과적합(Overfitting)을 방지하고 모델의 일반화 성능을 향상시키는 데 사용
- max_depth, min_samples_leaf 등 여러 하이퍼파라미터 값을 조정해 가지치기 할 수 있음
주요 하이퍼파라미터
| max_depth | 트리의 최대 깊이를 지정(기본값: None) |
| min_samples_split | 분할을 위해 노드에 필요한 최소 샘플 수를 지정(기본값: 2) |
| min_samples_leaf | 리프노드가 되기 위한 최소한의 샘플 수를 지정(기본값: 1) |
| max_leaf_nodes | 최선의 분할을 위해 고려할 Feature 수(기본값: None) |
| ccp_alpha | 리프 노드 최대 개수 |
export_graphviz로 시각화
# 시각화 모듈 불러오기
from sklearn.tree import export_graphviz
from IPython.display import Image
# 이미지 파일 만들기
export_graphviz(model, # 모델 이름
out_file='tree.dot', # 파일 이름
feature_names=x.columns, # Feature 이름
class_names=['die', 'survived'], # Target Class 이름
rounded=True, # 둥근 테두리
precision=2, # 불순도 소숫점 자리수
max_depth = 3, # 표시할 트리 깊이
filled=True) # 박스 내부 채우기
# 파일 변환
!dot tree.dot -Tpng -otree.png -Gdpi=300
# 이미지 파일 표시
Image(filename='tree.png')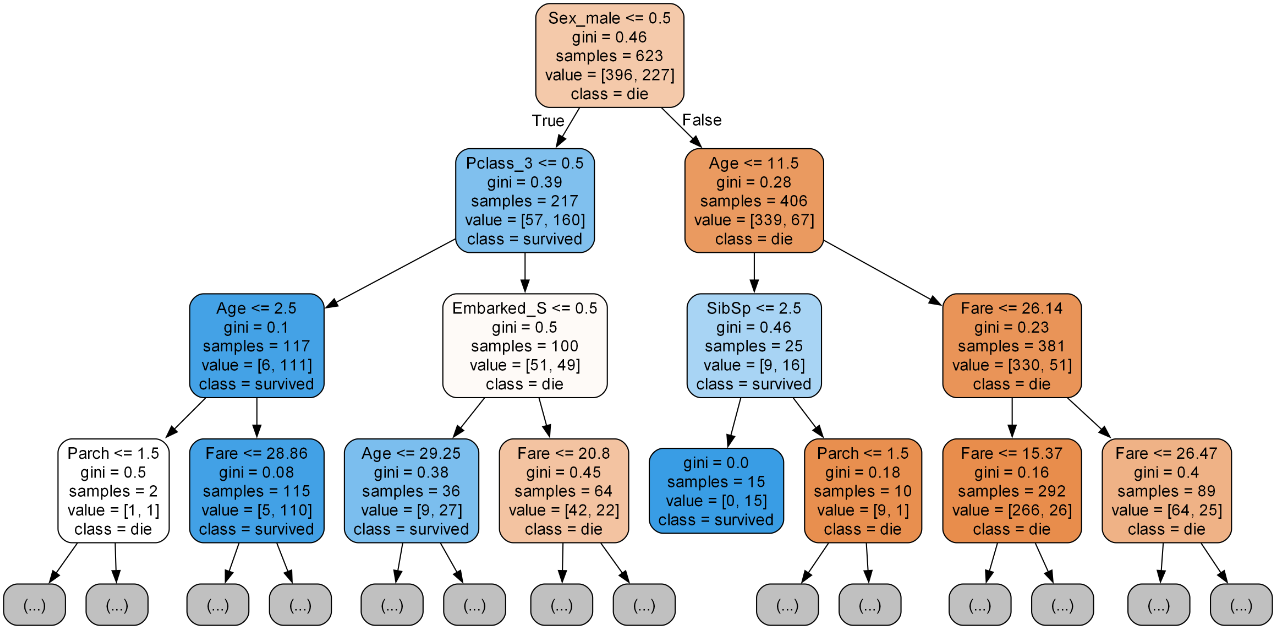
변수 중요도 시각화
# 데이터프레임 만들기
df = pd.DataFrame()
df['feature'] = list(x)
df['importance'] = model.feature_importances_
df.sort_values(by='importance', ascending=True, inplace=True)
# 시각화
plt.figure(figsize=(5, 5))
plt.barh(df['feature'], df['importance'])
plt.show()
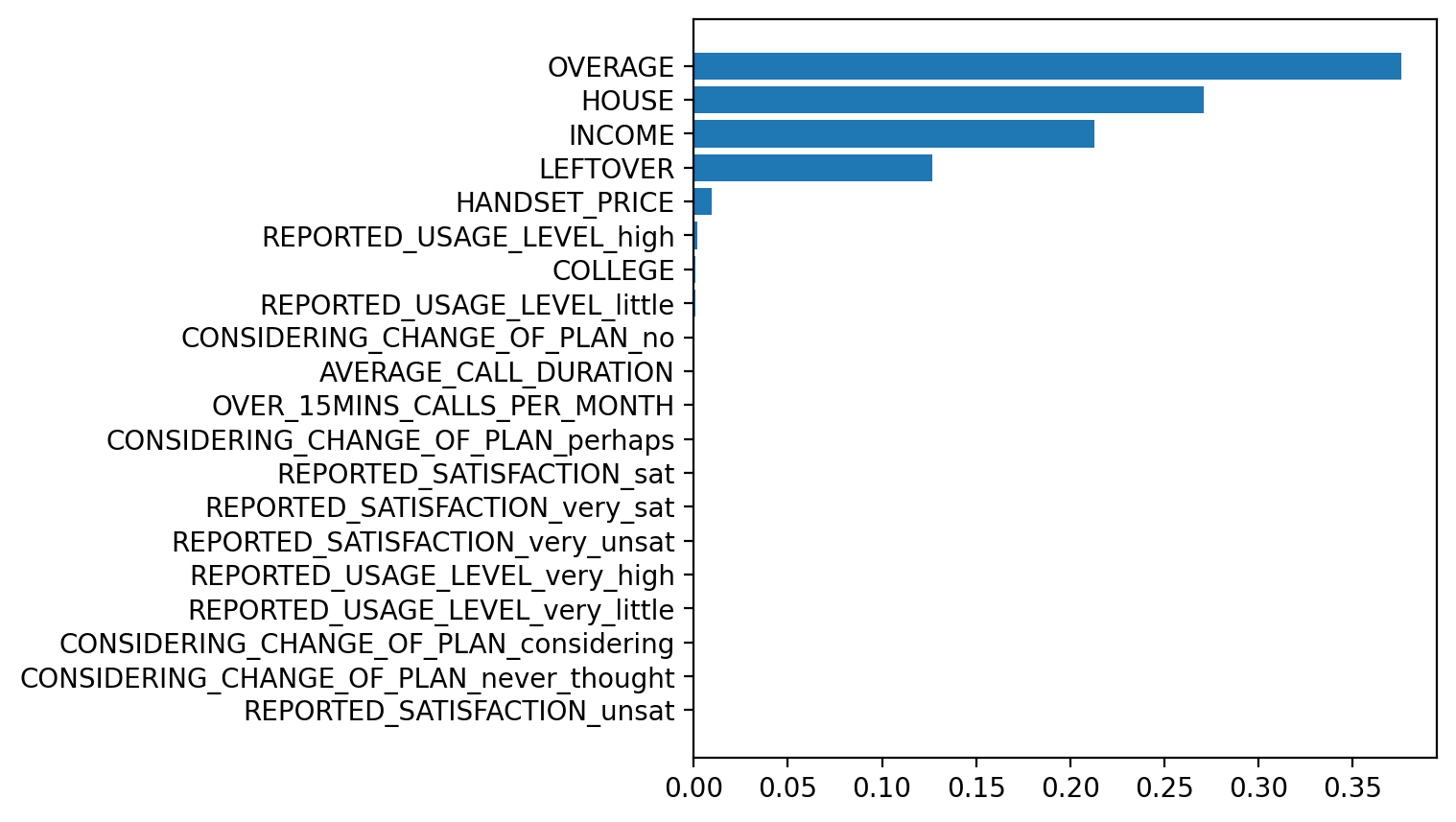
DecisionTree 알고리즘으로 모델 구현
# 알고리즘 함수
from sklearn.tree import DecisionTreeClassifier
# 성능평가 함수
from sklearn.metrics import confusion_matrix, classification_report
# 선언하기
model = DecisionTreeClassifier(max_depth=5)
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
4. Logistic Regression(로지스틱 회귀)
- 선형 회귀와 비슷하지만, 종속 변수가 범주형 데이터를 예측하는 데 사용
- 시그모이드(sigmoid)함수라고도 부름
- 0과 1 사이의 값을 출력하며 S 형태의 곡선을 그림
- 임계값은 보통 0.5로 설정되지만, 경우에 따라 저장 가능
- 임계값을 낮추면 더 많은 샘플이 positive class로 분류되지만, 이는 false positive(예측이 양성인데 실제로는 음성) 비율을 높일 수 있음.
- 반대로 임계값을 높이면 false negative(예측이 음성인데 실제로는 양성) 비율이 높아질 수 있음
Logistic Regression 알고리즘으로 모델 구현
# 알고리즘 함수
from sklearn.linear_model import LogisticRegression
# 성능평가 함수
from sklearn.metrics import confusion_matrix, classification_report
# 선언하기
model = LogisticRegression()
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
임곗값 조정
# 예측 확률
p = model.predict_proba(x_test)
# 1로 분류될 확률값
p1 = p[:, [0]]
p1[10:20]
# 임계값: 0.5
y_pred2 = [1 if x > 0.5 else 0 for x in p1]
# 임계값: 0.45
# y_pred2 = [1 if x > 0.45 else 0 for x in p1]
# 성능 평가
print(classification_report(y_test, y_pred2))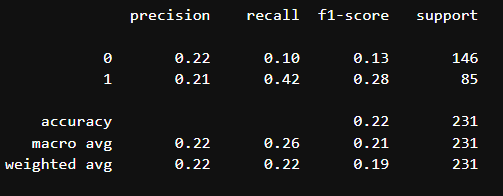
728x90
'KT AIVLE > DX 복습' 카테고리의 다른 글
| [KT AIVLE] DX트랙 머신러닝(7주차) 복습(비지도학습: 차원 축소, 클러스터링) (0) | 2024.04.04 |
|---|---|
| [KT AIVLE] DX트랙 머신러닝(7주차) 복습(K-Fold Cross Validation, Hyperparameter 튜닝, 앙상블) (0) | 2024.04.04 |
| [KT AIVLE] DX트랙 머신러닝(6주차) 복습(머신러닝, 분류, 회귀, 모델 성능 평가) (6) | 2024.03.28 |
| [KT AIVLE] DX트랙 데이터 분석 표현(6주차) 복습(Steamlit, Text elements, Chart elements, Map) (0) | 2024.03.25 |
| [KT AIVLE] DX트랙 데이터 수집(5주차) 복습(웹 크롤링, json, HTML, CSS) (2) | 2024.03.20 |