

728x90


얼마 전 데이터 분석 입문 공부할 때 유튜버 나도코딩님의 강의를 들으며 많은 도움을 받았는데 이번에 웹 크롤링에 관심이 생겨 알아보던 중 마침 좋은 영상이 있길래 공부하게 되었습니다. 파이썬 입문자분들 나도코딩님 강의 추천드립니다!
1. 웹 스크래핑과 웹 크롤링의 차이
- 웹 스크래핑: 웹 페이지에서 내가 원하는 데이터를 추출하는 것.
- 웹 크롤링: 웹 페이지에서 주어진 링크들을 따라가며 모든 데이터를 추출하는 것
2. HTML
웹 구성하는 세가지 요소
: HTML, CSS, JAVASCRIPT
HTML(Hyper Text Markup Language)
: 웹페이지를 만들 때 사용되는 언어
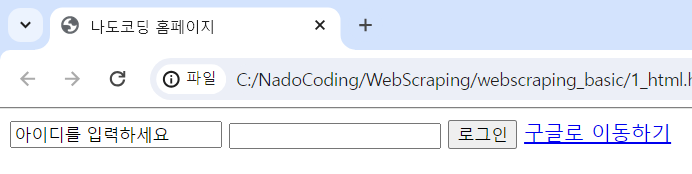
간단한 HTML 실습 - 로그인 페이지 만들기
<html>
<head>
<meta charset = "utf-8">
<title> 나도코딩 홈페이지</title>
</head>
<body>
<input type="text" value="아이디를 입력하세요">
<input type="password">
<input type="button" value="로그인">
<a href="http://google.com">구글로 이동하기</a>
</body>
</html>- head: 홈페이지의 제목이나 html 문서를 위한 선행작업
- body: 홈페이지 본문
- type과 value는 attribute라고 하며 element의 세부 속성을 의미
- 한글 깨짐 현상 해결을 위해 "utf-8"
- w3school에서 HTML 연습할 수 있음
3. XPath
XPath: HTML 내의 경로 접근을 위한 요소, 속성 등을 지정하는 언어
/학교/학년/반/학생[2]
//*[@학번="1-1-5"]
/html/body/div/span/a...
//*[@id="login"]
<학교 이름="나도 고등학교">
<학년 value = "1학년">
<반 value = "1반">
<학생 value="1번" 학번="1-1-1">이지현</학생>
<학생 value="2번" 학번="1-1-2">최다솔</학생>
<학생 value="3번" 학번="1-1-3">강채영</학생>
<학생 value="4번" 학번="1-1-4">지정민</학생>
<학생 value="5번" 학번="1-1-5">이지현</학생>
</반>
<반 value = "2반"/>
<반 value = "3반"/>
<반 value = "4반"/>
</학년>
<학년 value = "2학년"/> ... 3반 유재석 <...>
<학년 value = "3학년"/>
</학교>
4. Requests
- HTML 문서의 정보를 가져올 때 사용
import requests
# res = requests.get("http://naver.com")
res = requests.get("http://nadocoding.tistory.com")
print("응답코드 : ", res.status_code) # 200 : 정상 403 : 접근 권한 없음
if res.status_code == requests.codes.ok:
print("정상입니다.")
else:
print("문제가 생겼습니다. [에러코드 ", res.status_code, "]")
# if문 대신 사용 가능
res.raise_for_status() # HTML 문서를 가져오지 못한 경우 에러 발생 & 프로그램 종료
print("웹 스크래핑을 진행합니다")# 기본적인 형식
res = requests.get("http://nadocoding.tistory.com")
res.raise_for_status()
print(len(res.text))
print(res.text)
# 파일로 만들기
with open("mygoogle.html", "w", encoding="utf8") as f:
f.write(res.text)
5. 정규식
import re
#ca?e 검색 using 정규식
p = re.compile("ca.e")
# . : 하나의 문자 의미
# ^ : 문자열의 시작
# $ : 문자열의 끝
def print_match(m):
if m:
print("m.group(): ",m.group()) # 일치하는 문자열 반환
print("m.string: ",m.string) # 입력받은 문자열 반환
print("m.start(): ",m.start()) # 일치하는 문자열의 시작 index
print("m.end(): ",m.end()) # 일치하는 문자열의 끝 index
print("m.span(): ",m.span()) # 일치하는 문자열의 시작 / 끝 index
else:
print("매칭되지 않음")
m = p.match("careless")
# match : 주어진 문자열의 처음부터 일치하는지 확인
# group : 매치된 경우 매치된 문자열 출력 & 매치되지 않으면 에러 발생
m = p.search("good care")
# search : 주어진 문자열 중에 일치하는게 있는지 확인
lst = p.findall("good care cafe") #findall : 일치하는 모든 것을 리스트 형태로 반환- . : 하나의 문자 의미
- ^ : 문자열의 시작
- $ : 문자열의 끝
- p = re.compile("원하는 형태")
- m = p.match("비교할 문자열") : 주어진 문자열의 처음부터 일치하는지 확인
- m = p.search("비교할 문자열") : 주어진 문자열 중에 일치하는게 있는지 확인
- lst = p.findall("비교할 문자열") : 일치하는 모든 것을 "리스트" 형태로 반환
- 원하는 형태: 정규식
728x90
'PYTHON > 기타' 카테고리의 다른 글
| [나도코딩] 파이썬 웹 스크래핑(Web Scraping)(User_Agent, BeautifulSoup4) (2) | 2024.01.10 |
|---|---|
| [데이터 분석] 파이썬 태양열 신재생 에너지 분석(수평면 산란 일사량,풍속과 태양열 발전량의 상관관계) (0) | 2024.01.05 |
| [데이터 분석] Matplotlib, Seaborn 연습 (0) | 2024.01.05 |
| [데이터 분석] Pandas 연습 (0) | 2024.01.05 |
| [데이터 분석] 파이썬 쇼핑몰 매출 분석(월별, 요일별, 품목별, 연령대별)을 통한 인사이트 도출과 마케팅 전략 제안 (0) | 2023.12.12 |