

728x90

딥러닝 심화 복습
CNN(합성곱 신경망, Convolutional Neural Network)
- 입력 이미지를 효율적으로 처리하고 특징을 추출하여 이미지 분류, 객체 감지, 객체 분할 등의 작업을 수행하는 데 사용
1. Conv2D (Convolutional Layer)
- 합성곱 연산을 수행하는 레이어로, 입력 이미지에 필터를 적용하여 특징 맵을 생성
- 주로 이미지 처리에서 사용되며, 각 필터는 입력 이미지를 스캔하고 특정한 특징을 감지하는 역할
-
- filters = 32 (새롭게 제작하려는 feature Map의 수)
- kernel_size =(3,3) (필터의 가로세로 사이즈)
- Strides = (1,1) (필터의 이동 보폭)
- padding = 'Same' (feature map의 사이즈 유지, 외각의 정보를 조금이라도 더 반영)
- activation ='relu'
-
2. MaxPooling2D (MaxPooling Layer)
- 풀링 연산을 수행하는 레이어로, 특징 맵의 크기를 줄이는 역할
- 주로 공간 차원을 감소시켜 모델의 파라미터 수를 줄이고 계산량을 감소
- pool_size = (2,2) (풀링 필터의 가로세로 사이즈)
- strides = (2,2) (풀링 필터의 이동 보폭)
Feature Representation
- 연결된 것으로부터 기존에 없던 feature를 재표현/생성
CNN에서 Feature Representation이란?
- 위치정보를 보존한 채로 feature를 represent 한것.
- 이미지 구조를 살린 채로 문제 풀기: Convolutional Neural Network
잘학습된 CNN 특징
- 유용한 feature를 추출
- 위치정보를 보존
<Image Net> - object Detection 모델의 앞단에 쓰임(Backbone)
- AlexNet
- VGG
- GoogleNet
- ResNet
우리 문제(object Detection)에 맞게 레이어 추가/ 변형한 부분
- Head
Roboflow
- 컴퓨터 비전 및 머신러닝 프로젝트를 위한 플랫폼
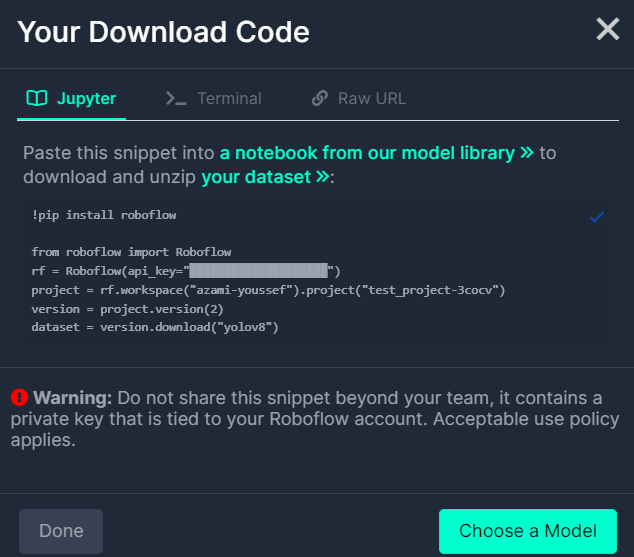
!pip install roboflow
from roboflow import Roboflow
rf = Roboflow(api_key="api_key")
project = rf.workspace("roboflow-universe-projects").project("construction-site-safety")
version = project.version(30)
dataset = version.download("yolov8")- 데이터셋은 Roboflow 사이트에서 코드 복사
# 모델링 라이브러리 설치하기
!pip install ultralytics
# 라이브러리 불러오기
from ultralytics import YOLO, settings
# 데이터셋, YAML 파일 경로 수정
# settings의 datasets_dir은 기본적으로 '/content/datasets/'로 되어있음
settings['datasets_dir'] = '/content/'
settings.update()
import yaml
# data.yaml 파일에서 train, val 데이터셋 경로를 ./train/images & ./valid/images로 수정

model = YOLO()
model.train(model = '/content/yolov8n.pt',
data = '/content/Construction-Site-Safety-30/data.yaml',
epochs = 10)
model.predict(source=image_path,
conf=0.25,
iou=0.7,
save=True,
)
CIFAR-10
- 이미지 분류를 위한 대표적인 데이터셋 중 하나
- 10개의 클래스로 구성된 60,000장의 32x32 크기 컬러 이미지로 이루어짐
!pip install -- upgrade keras
# 환경 설정, Pytorch, JAX도 가능
import os
os.environ['BACKEND'] = 'tensorflow'
# 라이브러리 설치
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import keras
# cifar-10 로드
(train_x, train_y), (test_x, test_y) = keras.datasets.cifar10.load_data()
# train_x: 32x32 크기 컬러 이미지, train_y: class 정보
train_x.shape, train_y.shape, test_x.shape, test_y.shape # ((50000, 32, 32, 3), (50000, 1), (10000, 32, 32, 3), (10000, 1))
# 이미지 라벨링
labels = {0: 'Airplane',
1: 'Automobile',
2: 'Bird',
3: 'Cat',
4: 'Deer',
5: 'Dog',
6: 'Frog',
7: 'Horse',
8: 'Ship',
9: 'Truck'}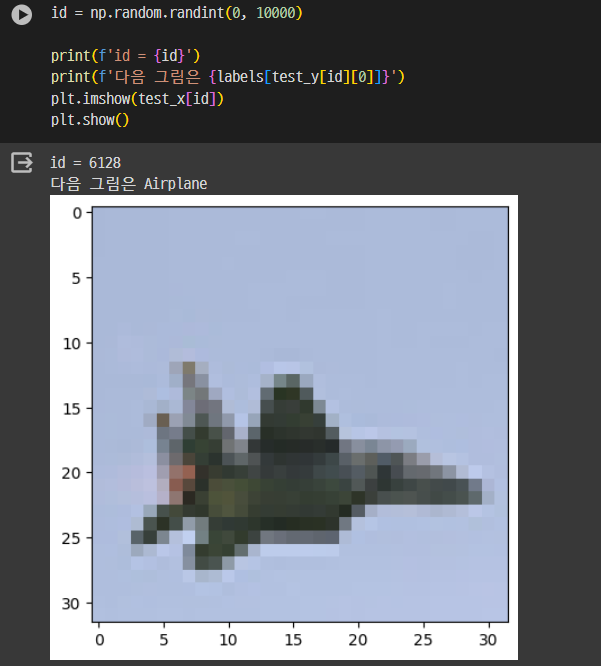
Modeling1
from keras.utils import clear_session
from keras.models import Sequential
from keras.layers import Input, Dense, Flatten# 1. 메모리 청소
clear_session()
# 2. 모델 선언 : 리스트 안에 추가하는 방식
model1 = Sequential([Input(shape=(32,32,3)),
keras.layers.Rescaling(1/255),
Flatten(),
Dense(64, activation='relu'),
Dense(64, activation='relu'),
Dense(128, activation='relu'),
Dense(128, activation='relu'),
Dense(256, activation='relu'),
Dense(256, activation='relu'),
Dense(10, activation='softmax'),
])
# 3. 레이어 블록 조립 : .add() 방식
# model1.add( Input(shape=(32,32,3)) )
# model1.add( keras.layers.Rescaling(1/255) )
# model1.add( Flatten() )
# model1.add( Dense(64, activation='relu'))
# model1.add( Dense(64, activation='relu'))
# model1.add( Dense(128, activation='relu'))
# model1.add( Dense(128, activation='relu'))
# model1.add( Dense(256, activation='relu'))
# model1.add( Dense(256, activation='relu'))
# model1.add( Dense(10, activation='softmax'))
# 4. 컴파일
model1.compile(optimizer='adam', loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
model1.summary()
- keras.layers.Rescaling(1/255): 이미지의 픽셀 값을 [0, 255] 범위에서 [0, 1] 범위로 조정, 정규화(normalization)
- Flatten(): 3D 이미지를 1D 벡터로 변환(평평하게 펼침)
모델 학습 중 조기 종료(early stopping)
from keras.callbacks import EarlyStopping
es = EarlyStopping(monitor='val_loss', # 얼리스토핑을 적용할 관측 지표
min_delta=0, # 임계값
patience=5, # 성능 개선이 발생하지 않았을 때, 몇 epochs 더 지켜볼 것인지
verbose=1, # 몇 번째 epochs에서 얼리스토핑이 되었는가 알려줌
restore_best_weights=True # 최적의 가중치를 가진 epoch 시점으로 가중치를 되돌림
)
model1.fit(train_x, train_y, validation_split=0.2,
epochs=10000, verbose=1,
callbacks=[es]
)
y_pred = model1.predict(test_x)
model1.evaluate(test_x, test_y)
Modeling2(Conv2D, Maxpool2D)
import keras
from keras.utils import clear_session
from keras.models import Sequential
from keras.layers import Input, Dense, Flatten
from keras.layers import Conv2D, MaxPool2D# 1. 메모리 청소
clear_session()
# 2. 모델 선언 : 리스트 안에 넣는 방식
model2 = Sequential([Input(shape=(32,32,3)),
keras.layers.Rescaling(1/255),
Conv2D(filters=64, # 서로 다른 필터 64개를 사용하겠다.
kernel_size=(3,3), # Conv2D 필터의 가로 세로 사이즈
strides=(1,1), # Conv2D 필터의 이동 보폭
padding='same', # 1.feature map 사이즈 유지 | 2.외곽 정보 더 반영
activation='relu', # 주의!
),
Conv2D(filters=64, # 서로 다른 필터 64개를 사용하겠다.
kernel_size=(3,3), # Conv2D 필터의 가로 세로 사이즈
strides=(1,1), # Conv2D 필터의 이동 보폭
padding='same', # 1.feature map 사이즈 유지 | 2.외곽 정보 더 반영
activation='relu', # 주의!
),
MaxPool2D(pool_size=(2,2),# pooling 필터의 가로 세로 사이즈
strides=(2,2) # pooling 필터의 이동 보폭 (기본적으로 pool_size를 따름)
),
Conv2D(filters=128, # 서로 다른 필터 64개를 사용하겠다.
kernel_size=(3,3), # Conv2D 필터의 가로 세로 사이즈
strides=(1,1), # Conv2D 필터의 이동 보폭
padding='same', # 1.feature map 사이즈 유지 | 2.외곽 정보 더 반영
activation='relu', # 주의!
),
Conv2D(filters=128, # 서로 다른 필터 64개를 사용하겠다.
kernel_size=(3,3), # Conv2D 필터의 가로 세로 사이즈
strides=(1,1), # Conv2D 필터의 이동 보폭
padding='same', # 1.feature map 사이즈 유지 | 2.외곽 정보 더 반영
activation='relu', # 주의!
),
MaxPool2D(pool_size=(2,2),# pooling 필터의 가로 세로 사이즈
strides=(2,2) # pooling 필터의 이동 보폭 (기본적으로 pool_size를 따름)
),
Conv2D(filters=256, # 서로 다른 필터 64개를 사용하겠다.
kernel_size=(3,3), # Conv2D 필터의 가로 세로 사이즈
strides=(1,1), # Conv2D 필터의 이동 보폭
padding='same', # 1.feature map 사이즈 유지 | 2.외곽 정보 더 반영
activation='relu', # 주의!
),
Conv2D(filters=256, # 서로 다른 필터 64개를 사용하겠다.
kernel_size=(3,3), # Conv2D 필터의 가로 세로 사이즈
strides=(1,1), # Conv2D 필터의 이동 보폭
padding='same', # 1.feature map 사이즈 유지 | 2.외곽 정보 더 반영
activation='relu', # 주의!
),
MaxPool2D(pool_size=(2,2),# pooling 필터의 가로 세로 사이즈
strides=(2,2) # pooling 필터의 이동 보폭 (기본적으로 pool_size를 따름)
),
Flatten(),
Dense(10, activation='softmax')
])
# 3. 컴파일
model2.compile(optimizer='adam', loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
model2.summary()
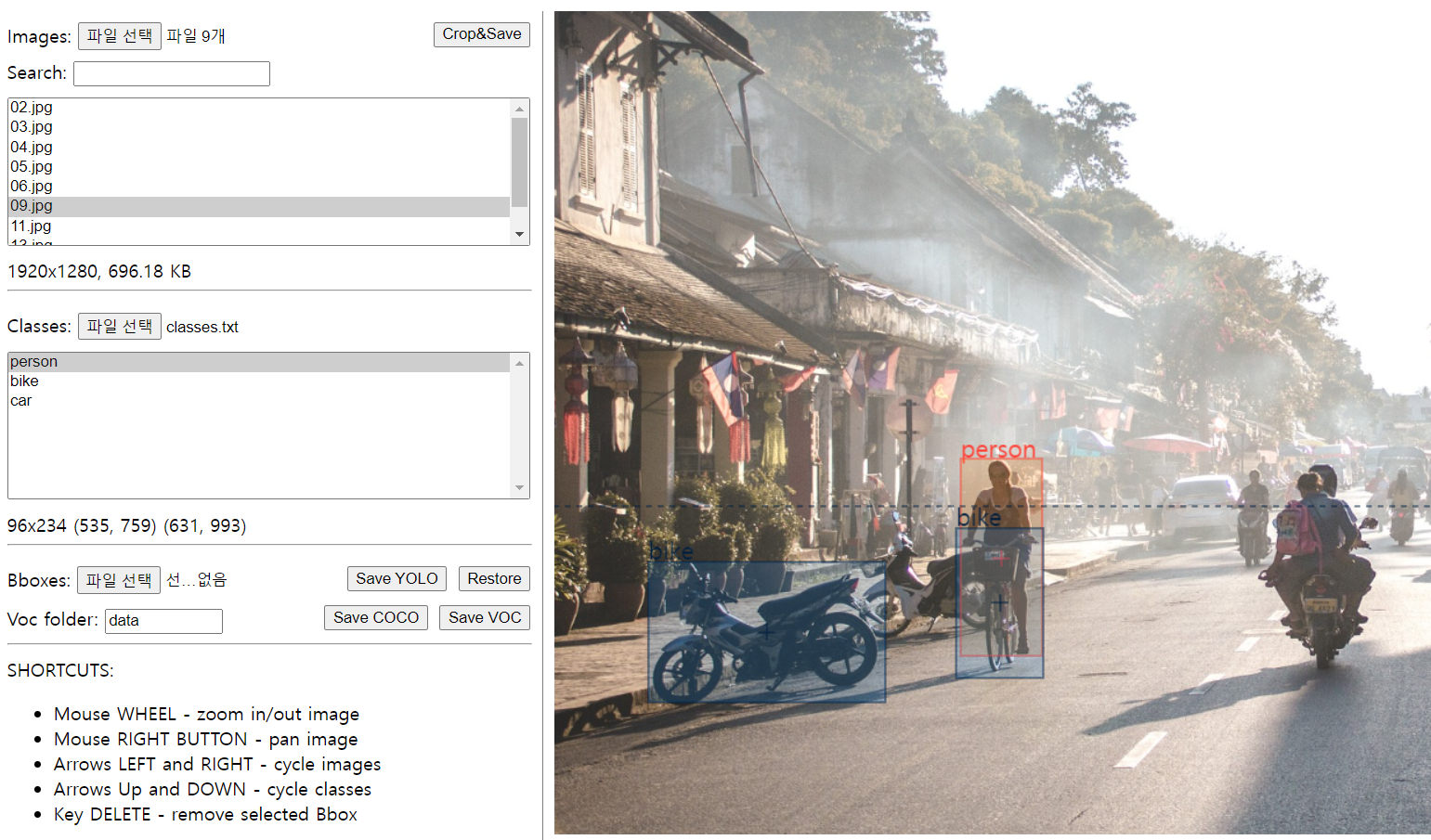
Annotation
Local에서 Dataset 만들고 YOLO 모델 동작하도록 연습
- 이미지 수집
- 폴더 구조(YOLO에서 요구하는 형식으로 맞추기)
- YAML
- Class 수
- Class 이름
- 데이터셋 경로
- YOLO 실행
728x90
'KT AIVLE > DX 복습' 카테고리의 다른 글
| [KT AIVLE] DX트랙 IT 인프라(12주차) 복습(IT 인프라: 가상머신, 컨테이너, 리눅스, 보안) (0) | 2024.05.10 |
|---|---|
| [KT AIVLE] DX트랙 IT 인프라(12주차) 복습(IT 인프라: 스위치, OSI 7계층, 라우터) (0) | 2024.05.09 |
| [KT AIVLE] DX트랙 딥러닝(9주차) 복습(딥러닝 심화: Object Detection, YOLO v8) (0) | 2024.04.23 |
| [KT AIVLE] DX트랙 딥러닝(8주차) 복습(딥러닝 기초: Regression, 이진분류, 다중분류) (0) | 2024.04.13 |
| [KT AIVLE] DX트랙 머신러닝(7주차) 복습(비지도학습: 차원 축소, 클러스터링) (0) | 2024.04.04 |