

728x90

데이터 다듬기 복습
5. 판다스(Pandas) 데이터 프레임 변경
열 이름 변경
1) 일부 열 이름 변경
- rename() 메서드를 사용해 변경 전후의 열 이름을 딕셔너리 형태로 나열
- inplace=True 옵션을 설정해야 변경 사항이 실제로 반영
# rename() 함수로 열 이름 변경
tip.rename(columns = {'total_bill_amount': 'total_bill',
'male_female' : 'sex',
'dinner_lunch' : 'time'}, inplace =True)
2) 모든 열이름 변경
- 모든 열 이름을 변경할 때는 columns 속성을 변경
- 변경이 필요없는 열은기존 이름 부여
# 모든 열 이름 변경
tip.columns = ['total_bill', 'sex', 'time']
열 추가
- 새로운 열을 추가해 기존 데이터에서 계산된 결괏값을 저장해야 할 경우
- insert() 메서드 사용해서 웒는 위치에 열 추가 가능
# final_amt 열 추가: final_amt = total_bill + tip
tip['final_amt'] = tip['total_bill'] + tip['tip']
# tip 열 앞에 div_tb 열 추가: div_tb = total_bill / size
tip.insert(1, 'div_tb', tip['total_bill'] / tip['size'])
열 삭제
1) 열 하나 삭제
- drop() 메서드를 사용해 열을 삭제
- axis = 0: 행 삭제(기본 값)
- axis = 1: 열 삭제
- inplace=True 옵션 지정해야 실제로 반영
2) 여러 열 삭제
- df.drop( ['열이름1', '열이름2'], axis=1, inplace=True)
- 열 이름 리스트로 변수 선언도 가능
범주값 변경
- map(), replace() 메서드로 범주형 값을 다른 값으로 변경 가능
- 바꾸려고 하는 값의 개수 먼저 확인 df['열 이름'].value_counts()
# map()
df['x'] = df['x'].map({'A': 1, 'B': 2})
# replace()
df['x'] = df['x'].replace({'A': 1, 'B': 2})
범주값 만들기
- 이산화(Discretization): 연속값을 구간을 나누어 범주값으로 표현하는 과정
1) cut() 함수
- 크기를 기준으로 구간을 나누고 싶을 때 cut()함수를 사용
- 범위 개수를 지정하면 자동으로 크기를 기준으로 나눔
- df['그룹 이름'] = pd.cut(df['열 이름'], bins=bin, labels=label)
# tip 크기를 기준으로 4구간(a ~ d)으로 나누기
tip['tip_grp'] = pd.cut(tip['tip'], 4, labels = list('abcd'))
bin = [-np.inf, 60, 70, 80, 90, np.inf]
label = list('abcd')
df['Group1'] = pd.cut(df['score'], bins=bin, labels=label)
2) qcut() 함수
- 개수를 기준으로 구간을 나누고 싶을 때 qcut()함수를 사용
- 범위 개수를 지정하면 자동으로 동일한 개수를 갖는 구간이 만들어짐
- df['그룹 이름'] = pd.qcut(df['열 이름'], 구간 개수, list('구간 이름'))
# 같은 개수의 total_bill을 갖는 4개 구간으로 나누기
tip['bill_grp2'] = pd.qcut(tip['total_bill'], 4, list('abcd'))
# 사분위수
q1 = tip['total_bill'].describe()['25%']
q2 = tip['total_bill'].describe()['50%']
q3 = tip['total_bill'].describe()['75%']
6. 판다스(Pandas) 데이터 프레임 변경 (2)
결측치 찾기
# 결측치 찾기
df.isnull() # NaN인 요소는 True, 그렇지 않은 요소는 False를 반환
air.notnull() # 전체 데이터 중에서 결측치는 False로 표시
df.info() # 결측치 개수 확인
df.describe() # 결측치를 포함한 행의 개수 확인
df.isnull().sum() # 각 열의 결측치 개수 확인
df.isna().sum() # 열의 결측치 개수 확인
df.isna().sum() / len(air) * 100 # 결측치 비율 확인
df.isna().mean() * 100 # 결측치 비율 확인
결측치 제거
- dropna() 메서드로 결측치가 있는 열이나 행을 제거할 수 있음
- inplace=True 옵션 지정해야 해당 데이터프레임에 실제로 반영
- axis=0: 행 제거(기본값)
- axis=1: 열 제거
1) 어떤 열이든 결측치가 있는 행 제거
# 결측치가 하나라도 있는 행 제거
df.dropna(axis = 0, inplace = True)
2) 특정 열에 결측치가 있는 행 제거
- subset 옵션에 열을 지정해 해당 열에 결측치가 있는 행을 제거
# 특정 열에 있는 결측치 행을 제거
df.dropna(subset=['열 이름'], axis=0, inplace=True)
3) 결측치가 있는 모든 열 제거
- axis=1 옵션을 지정해서 열을 제거
결측치 채우기
# 1) 결측치를 평균값으로 채우기
df['열 이름'].fillna(df['열 이름'].mean(), inplace=True)
# 2) 특정 열의 결측치를 특정 값으로 채우기
df['열 이름'].fillna(0, inplace=True)
3) 직전 행의 값 또는 바로 다음 행의 값으로 채우기
- 날짜 또는 시간의 흐름에 따른값을 갖는 시계열 데이터 처리시 유용
- method='ffill': 바로 앞의 값으로 변경(Forward Fill)
- method='bfill': 바로 다음 값으로 변경(Backward Fill)
# 결측치를 바로 앞의 값으로 채우기
df['열 이름'].fillna(method='ffill', inplace=True)
# 결측치를 바로 뒤의 값으로 채우기
df['열 이름'].fillna(method='bfill', inplace=True)
4) 선형보간법으로 채우기
- interpolate() 메서드를 사용해 선형보간법으로 채울 수 있음
# 선형보간법으로 채우기
df['열 이름'].interpolate(method='linear', inplace=True)
가변수(Dummy Variable) 만들기
- 가변수는 일정하게 정해진 범위의 값을 갖는 데이터(범주형 데이터)를 독립된 열로 변환한 것
- 특히 범주형 문자열 데이터는 머신러닝 알고리즘에 사용하려면 숫자로 변환해야 함
- 가변수를 만드는 과정을 One-Hot-Encoding 이라고 부르기도 함
- get_dummies() 함수를 사용해서 가변수를 쉽게 만들 수 있음
범주형 변수 확인
- 문자열 값을 갖는 열이 범수형값을 갖는 경우가 많음
- info()로 object 확인
변수 개별 처리
- columns 옵션에 열을 하나 지정해 처리할 수 있음
- 자동으로 원본 열이 제거되고, 열 이름이 prefix로 사용
- 다중공선성 문제를 없애기 위해 drop_first=True 옵션을 지정
pd.get_dummies(data, columns = ['열 이름'], drop_first=False, dtype=None)
# data: 변환할 데이터프레임입니다.
# columns: 가변수화를 수행할 열 이름을 지정
# drop_first: 첫 번째 카테고리 값을 삭제할지 여부를 결정하는 부울 값
# dtype: 결과 데이터프레임의 데이터 유형을 지정
일괄 처리
- columns 옵션에 대상 열을 리스트로 지정해 한 번에 처리
- 자동으로 원본 열 제거, 열 이름이 prefix로 사용됨
- columns 옵션을 지정하지 않으면 문자열 값을 갖는 열 모두를 대상으로 함
7. 판다스(Pandas) 데이터 프레임 변경 (3)
데이터 프레임 합치기(Concat)
- concat() 함수를 사용해 인덱스 값을 기준으로 두 데이터프레임을 가로나 세로로 합침
1) 가로로 합치기
- 가로로 합칠 때는 axis=1 옵션을 지정
- join='outer'는 기본 옵션값으로 생략이 가능
- outer 옵션을 지정하면 결측치가 생김
- inner 옵션을 지정하면 매핑되지 못한 행은 제외
# outer
pop = pd.concat([pop01, pop02])
# inner
pop = pd.concat([pop01, pop02], axis = 1, join = 'inner')
2) 세로로 합치기
- 세로로 합칠 때는 axis=0 옵션을 지정
- 세로로 합해지면 인덱스 값이 중복될 수도 있으므로 인덱스 초기화
데이터 프레임 조인(Merge)
- merge() 함수를 사용 두 데이터 프레임을 지정한 키 값을 기준으로 병합
- join='inner'는 기본 옵션값으로 생략이 가능
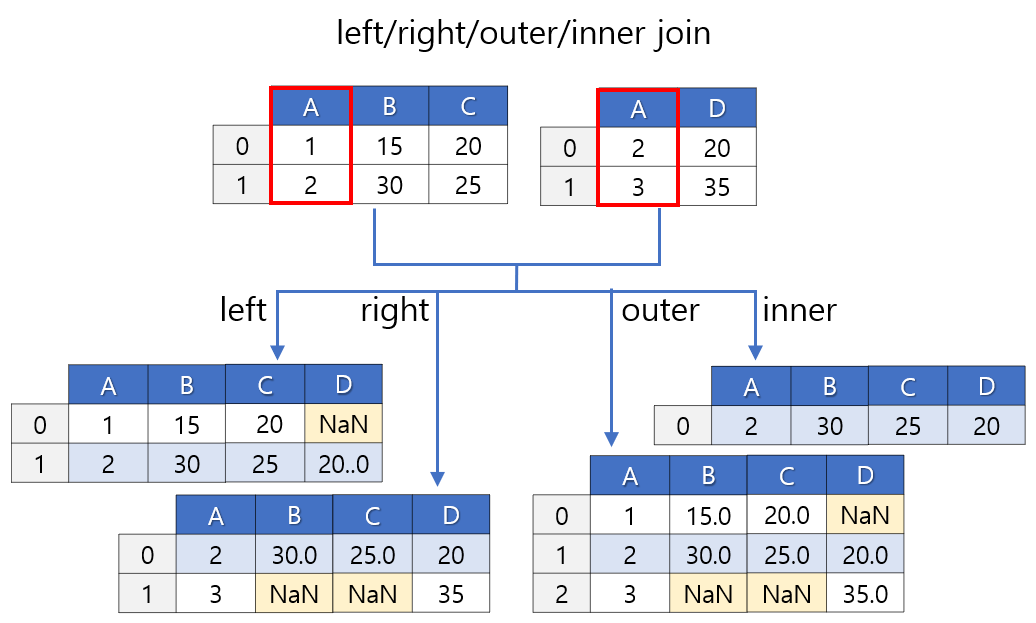
#inner
변수 = pd.merge(df1, df2, on='조인할 열 이름', how='inner')
#outer
변수 = pd.merge(df1, df2, on='조인할 열 이름', how='outer')
- left: 왼쪽 데이터프레임의 모든 행을 유지하면서 오른쪽 데이터프레임의 해당 행이 없는 경우 NaN으로 채우고자 할 때 사용 (right는 left 반대)
- inner: 두 데이터프레임의 공통된 행만을 유지하고자 할 때 사용
- outer: 두 데이터프레임의 모든 행을 유지하고자 하며, NaN으로 채워지는 값이 발생할 수 있음
728x90
'KT AIVLE > DX 복습' 카테고리의 다른 글
| [KT AIVLE] DX트랙 데이터 수집(5주차) 복습(웹 크롤링, json, HTML, CSS) (2) | 2024.03.20 |
|---|---|
| [KT AIVLE] DX트랙 데이터 분석(4주차) 복습(가설검정, 이변량분석, T-Test, ANOVA, 카이제곱검정 ) (4) | 2024.03.16 |
| [KT AIVLE] DX트랙 데이터 분석(4주차) 복습(데이터 분석 방법론, EDA&CDA, 시각화라이브러리, 단변량 분석, 숫자형·범주형 변수) (2) | 2024.03.12 |
| [KT AIVLE] DX트랙 데이터 다듬기(2~3주차) 복습(넘파이 연산, 판다스 데이터프레임 함수, 조회, 집계) (0) | 2024.03.10 |
| [KT AIVLE] KT 에이블스쿨 5기 DX트랙 데이터 다루기(1~2주차) 복습 (1) | 2024.03.06 |