


데이터 분석 복습
6. 가설검정
가설검정(hypothesis test)
- 수집한 데이터로 가설에 대해 타당성을 입증하는 것
모집단과 표본
- 모집단: 알고 싶은 대상 전체 데이터
- 표본: 그 대상의 일부 데이터
귀무가설(null hypothesis)
- 현재까지 알려진 사실을 기준으로 설정한 가설
- 차이가 없다
대립가설(alternative hypothesis)
- 새롭게 주장하고자 하는 가설
- 차이가 있다
통계적 검정
- 표본으로부터 대립가설을 확인하고, 모집단에서도 맞을 것이라 주장
- 분포 + 판단 기준 필요
- p-value 계산(차이 값이 클 수록 p-value 작아 짐)
- 0.05 보다는 p-value가 작아야, 차이가 있다고 판단
단측검정
- ex) A매장과 B매장 중 어디의 수요량이 더 큰가?
양측검정(주로 사용)
- ex) 매장 간에 수요량의 차이가 있나?
검정 통계량
- 가설 검정을 하기 위한 차이 값
- t통계량
- x^2(카이제곱) 통계량
- f 통계량
- 각각 기준 대비 차이로 계산
7. 두 변수의 관계 분석(이변량분석): 숫자 → 숫자
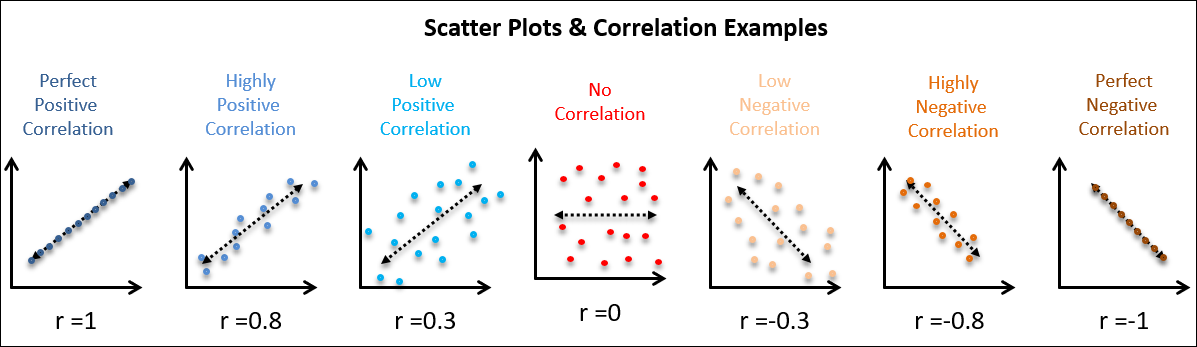
산점도(scatter)
- 두 숫자형 변수의 관계를 나타내는 그래프
- 숫자 vs 숫자를 비교할 때 중요한 관점 직선(Linearity)
- plt.scatter( x축 값, y축 값 )
- plt.scatter( ‘x변수’, ‘y변수’, data = df)
- seaborn • sns.scatterplot( ‘x변수’, ‘y변수’, data = df)
강한관계 판별
- 얼마나 직선에 모여 있는가
- x, y의 관계를 얼마나 직선으로 잘 설명할 수 있는가
sns.pairplot(dataframe)
- 숫자형 변수들에 대한 산점도를 한꺼번에 그려줌
- 변수와 데이터가 많다면 많은 시간 소요
sns.pairplot(air, kind='reg' ) # regression, 직선 표시
plt.show()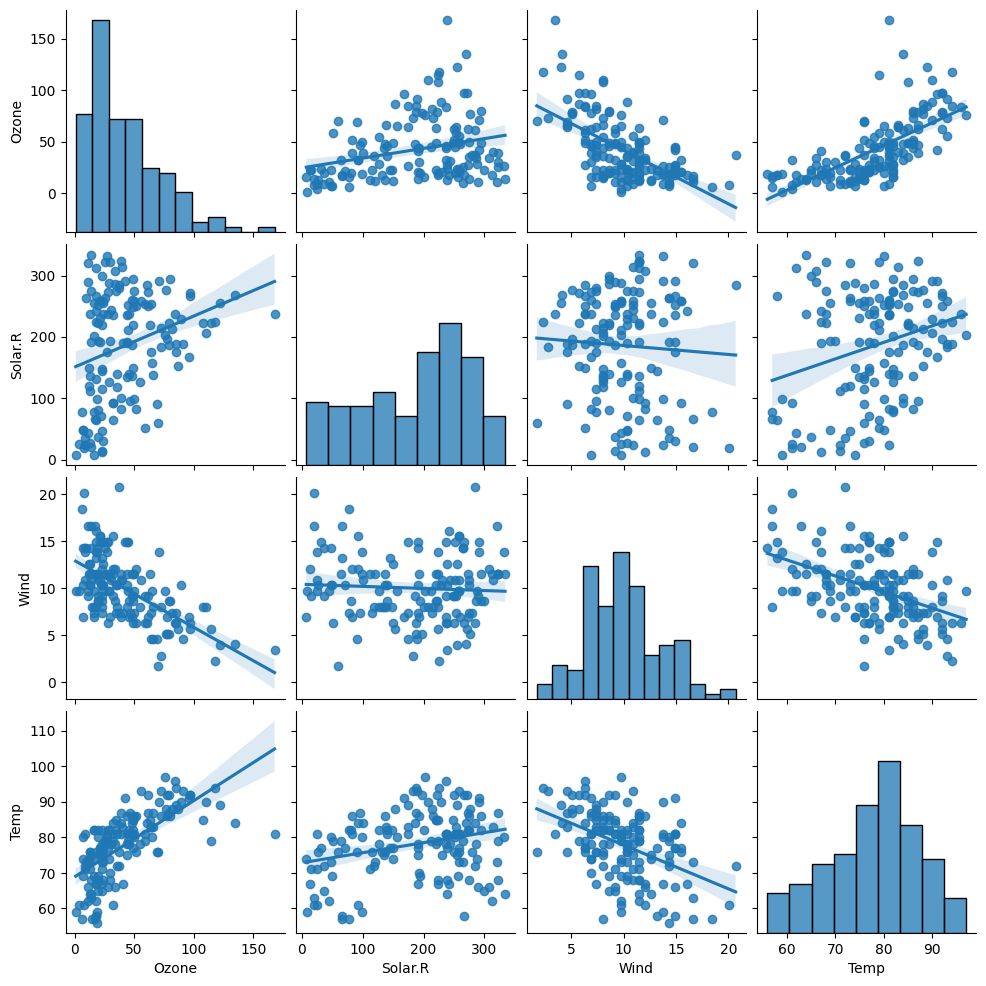
수치화: 상관계수, 상관분석
상관분석
- 상관계수가 유의미한 지를 검정
상관계수(correlation coefficient)
- 관계를 수치화
- r로 표현
- -1 ~ 1 사이의 값
- -1, 1에 가까울 수록 강한 상관관계를 나타내고 0에 가까울 수록 약한 상관관계
대략적인 기준
| 강한 | 0.5 < |r| <= 1 |
| 중간 | 0.2 < |r| <= 0.5 |
| 약한 | 0.1 < |r| <= 0.2 |
| (거의)없음 | |r| <= 0.1 |
상관계수의 유의성 검정
- 상관계수의 크기로 판단
- 상관분석을 통해서 검정(p value로 판단)
spst.pearsonr
- 피어슨 상관분석 함수
- Nan있으면 x
- (상관계수, p-value)로 출력
import scipy.stats as spst
spst.pearsonr(air['Temp'], air['Ozone'])
# PearsonRResult(statistic=0.6833717861490114, pvalue=2.197769800200284e-22)
p-value
- 관계를 수치화 한 값이 유의미한지 판단하는 숫자
- P-value < 0.05 이면, 두 변수 간에 관계가 있음 (상관계수가 의미 o)
- P-value >= 0.05 이면, 두 변수 간에 관계가 없음 (상관계수가 의미 x)
df.corr()
- 전체 상관계수 확인
- 대각선을 기준으로 위, 아래는 동일한 값
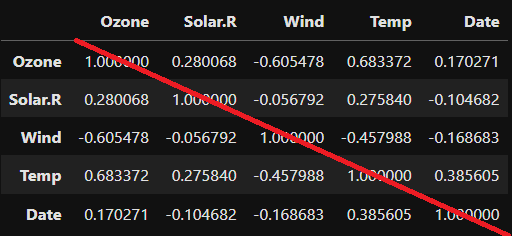
상관계수는 직선의 관계(선형관계)만 수치화
- 직선의 기울기, 비선형 관계는 고려하지 않음
숫자 → 숫자 정리
| Focus | 직선(선형성, Linearity) 얼마나 직선으로 잘 설명할 수 있는가? 얼마나 직선에 점들이 모여 있는가? |
| 시각화 | 산점도(scatter) 두 숫자형 변수의 관계를 눈으로 확인 직선의 관계를 확인하지만, 직선이 아닌 관계(패턴)도 확인 |
| 수치화 | 상관분석 상관계수: -1 혹은 1에 가까울 수록 강한 상관관계, 0에 가까울 수록 약한 상관관계 p-value : 0.05보다 작으면 상관관계가 있다고 판단 |
8. 평균 추정과 신뢰구간
평균과 분산, 표준편차
분산(Var, Variance), 표준편차(SD, Standard Deviation)
- 이탈도(deviation): 평균으로부터 얼마나 벗어나 있는지를 나타내는 값

분산
- 전체 원소에 대한 평균 구하기
- 각 원소에서 평균을 뺀 후, 제곱하기
- 2번에서 구한 값들의 모두 더한 후, 원소 개수로 나누기
표준편차
- 분산의 제곱근
- 데이터가 평균에서 얼마나 퍼져 있는지를 나타내는 측정 지표
- 표준편차가 작을수록 데이터가 평균 주변에 모여 있고, 클수록 퍼져 있는 것을 의미
print(f'평균 : {a.mean()}')
print(f'분산 : {a.var()}')
print(f'표준편차 : {a.std()}')
모집단과 표본
전수조사
- 전체(모집단)를 조사
- 장점: 정확하고 오차가 없음
- 단점: 비용, 시간 과다
표본조사
- 추출 방식: 많은 수, 무작위
- 장점: 적절한 비용, 시간
- 단점: 오차 존재
표본평균
- 표본(Sample)은 전체 모집단(Population)에서 추출한 일부 데이터
- 표본평균은 해당 표본의 데이터 값들의 평균
- 모평균에 대한 추정치
- 모평균은 모집단의 모든 데이터 값들의 평균을 의미
| μ(뮤) | 모평균 |
| σ^2(시그마) | 모분산(모표준편차) |
| x̄ (x-bar) | 표본평균 |
| s^2 | 표본분산(표본표준편차 |
중심극한정리(Central Limit Theorem)
- 표본의 크기(n)가 클 수록 정규분포 모양이 중심(Central)에 가까워지는(Limit) 좁은 형태가 됨
- 즉, 표본의 크기가 충분히 클수록 표본 평균의 분포가 정규 분포에 가까워짐
표준오차(Standard Error)
- 표본의 표본평균과 모집단의 모평균 간의 차이를 나타내는 측정 지표
- 추정치에 존재하는 오차
- 표준오차가 작을수록 표본평균이 모평균에 더 가깝다는 것을 의미
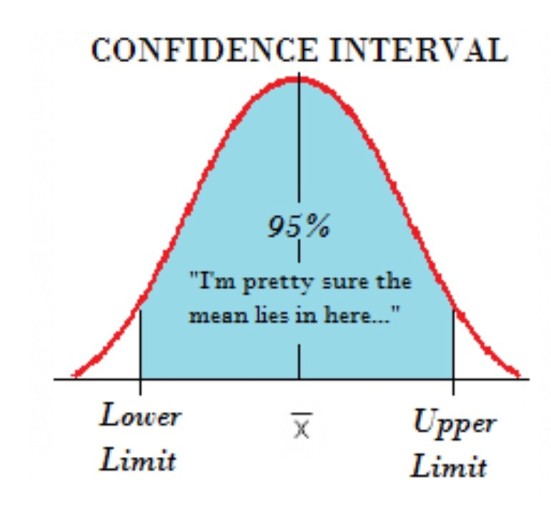
95% 신뢰구간(Confidence Interval)
- 표준오차를 바탕으로 95% 확률 구간을 구할 수 있음
- 신뢰구간 안에 모평균이 포함될 확률이 95%
9. 두 변수의 관계 분석(이변량분석): 범주 → 숫자
시각화: 범주 → 숫자
sns.barplot
sns.barplot(x="x축컬럼명(범주)", y="y축컬럼명(숫자)", data=data)
plt.grid()
plt.show()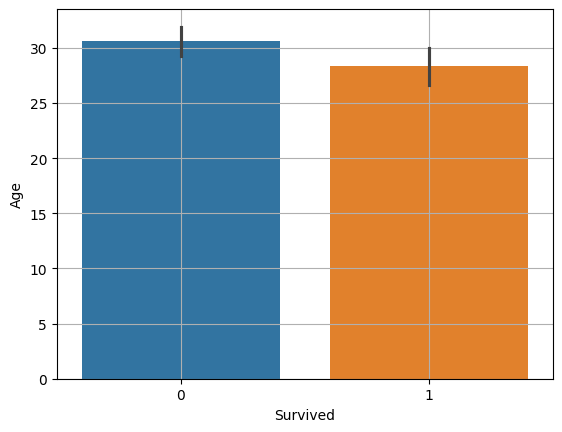
그래프 가운데 검은색 선은 95% 신뢰구간을 의미
수치화: t-test, anova(분산분석)
t-test
- 두 그룹 간의 평균 차이(t통계량)가 통계적으로 유의미한지를 검정하는 방법
- 범주의 수 2개일 때 사용.
- P-value < 0.05
- t 통계량 < -2 혹은 t 통계량 > 2
- ttest_ind(B, A, equal_var = False)
# NaN 행 제외
temp = titanic.loc[titanic['Age'].notnull()]
# 두 그룹으로 데이터 저장
died = temp.loc[temp['Survived']==0, 'Age']
survived = temp.loc[temp['Survived']==1, 'Age']
# t-test
spst.ttest_ind(died, survived)- TtestResult(statistic=2.06668694625381, pvalue=0.03912465401348249, df=712.0)
- t - 통계량: 2.067 , 2보다 크므로, 차이가 있으나 크지 않음
- P-value: 0.039, 0.05보다 작으므로, 차이가 있으나 크지 않음
ANOVA (ANalysis of Variance)
- 세 개 이상의 그룹 간의 평균 차이를 비교하는 방법
- ANOVA는 그룹 간의 평균 차이가 통계적으로 유의미한지를 검정
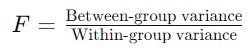
- F 통계량이 큰 경우, 그룹 간의 평균 차이가 통계적으로 유의미
- (집단 간 분산) / (집단 내 분산)
- 집단 간 분산 = 전체 평균 − 각 집단 평균, 집단 내 분산 = 각 집단의 평균 − 개별 값
- 분산분석(ANOVA)은 전체 평균대비 각 그룹간 차이가 있는지만 제공
- 추가적인 사후 분석을 통해 어떤 그룹 간에 차이가 있는지를 확인
# NaN 행 제외
temp = titanic.loc[titanic['Age'].notnull()]
# 그룹별 저장
P_1 = temp.loc[temp.Pclass == 1, 'Age']
P_2 = temp.loc[temp.Pclass == 2, 'Age']
P_3 = temp.loc[temp.Pclass == 3, 'Age']
# 분산분석
spst.f_oneway(P_1, P_2, P_3)- F_onewayResult(statistic=57.443484340676214, pvalue=7.487984171959904e-24)
- F 통계량: 57.44, 그룹 간의 평균 차이가 크다는 것
- p-value: 7.49e-24 (거의 0에 가까운 매우 작은 값)
10. 두 변수의 관계 분석(이변량분석): 범주 → 범주
교차표 (Crosstab)
pd.crosstab(행, 열, normalize =)
- normalize 옵션 : 비율로 변환
- columns : 열 기준 100%
- index : 행 기준 100%
- all : 전체 기준 100%
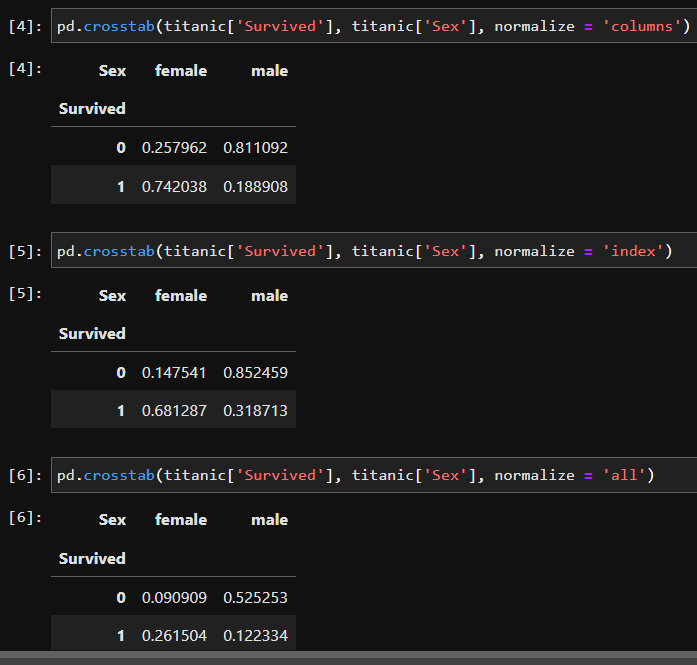
- normalize='columns': 각 열의 합으로 각 열의 값을 나누어 정규화한다. 따라서 각 셀의 값은 해당 열의 전체 합 대비 비율을 나타낸다.
- normalize='index': 각 행의 합으로 각 행의 값을 나누어 정규화한다. 따라서 각 셀의 값은 해당 행의 전체 합 대비 비율을 나타낸다.
-
- normalize='all': 전체 데이터의 총 합으로 모든 값을 나누어 정규화한다. 따라서 각 셀의 값은 전체 데이터의 비율을 나타낸다.
시각화: 범주 → 범주
mosaic plot
from statsmodels.graphics.mosaicplot
import mosaic
mosaic(titanic, ['Pclass','Survived'])
plt.axhline(1- titanic['Survived'].mean(),color = 'r') # 전체 평균
plt.show()
- x축 길이는 각 객실등급별 승객비율을 의미
- 3등급 객실 기준 y축은 3등급 객실 승객 중에서 사망, 생존 비율을 의미
카이제곱검정
카이 제곱 통계량
- 기대빈도와 실제 데이터의 차이
- 기대빈도: 아무런 관련이 없을 때 나올 수 있는 빈도수

- 클수록 기대빈도로부터 실제 값에 차이가 크다는 의미.
- 범주의 수가 늘어날 수록 값은 커지게 되어 있음.
- 자유도의 2배 이상인 경우, 차이가 있다고 봄
자유도
- 범주형 변수의 자유도
- 범주의 수 - 1
- 카이제곱 검정에서 자유도
- (x 변수의 자유도) * (y 변수의 자유도)
카이제곱 검정
# 1) 먼저 교차표 집계- normalize 하면 안 됨
table = pd.crosstab(titanic['Survived'], titanic['Pclass'])
print(table)
print('-' * 50)
# 2) 카이제곱검정
spst.chi2_contingency(table)
# 결과
# Chi2ContingencyResult(statistic=102.88898875696056, pvalue=4.549251711298793e-23, dof=2,
# expected_freq=array([[133.09090909, 113.37373737, 302.53535354], [ 82.90909091, 70.62626263, 188.46464646]]))
결과
➀ 카이제곱 통계량: 102.88898875696056
➁ P-value: 4.549251711298793e-23
➂ 자유도(dof) : Pclass 자유도(3-1) * Survived 자유도(2-1) , 2
➃ 기대빈도 : 계산된 값, ([[133.09090909, 113.37373737, 302.53535354], [ 82.90909091, 70.62626263, 188.46464646]]))
11. 두 변수의 관계 분석(이변량분석): 숫자 → 범주
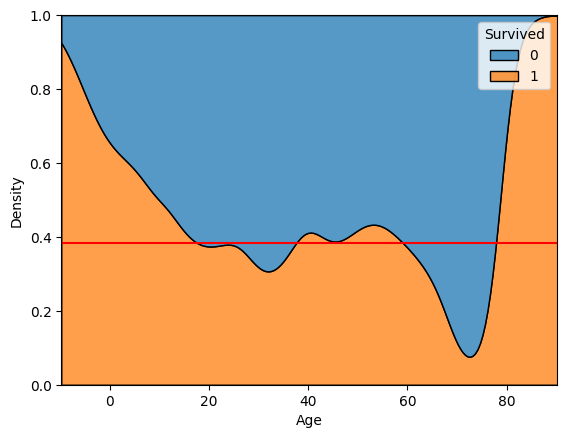
sns.kdeplot()
- common_norm = False
- multiple = 'fill'
sns.kdeplot(x='Age', data = titanic, hue ='Survived',
common_norm = False)
plt.grid()
plt.show()
sns.kdeplot(x='Age', data = titanic, hue ='Survived'
, multiple = 'fill')
plt.axhline(titanic['Survived'].mean(), color = 'r')
plt.show()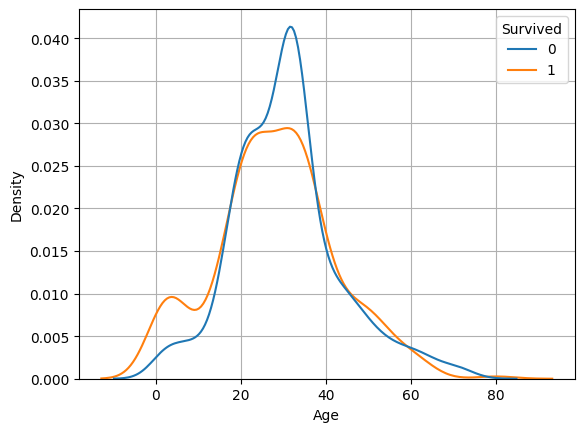
12. 시계열 데이터 분석
시계열 데이터 분석
- 데이터 분석 단위(행) 간에 시간 순서(sequence)가 있는 데이터
- 시계열 데이터 구분은, 비즈니스 이해단계에서 문제정의시 결정
- 해결해야 할 문제가 시간 순서 관점이 필요한지 아닌지
시간의 흐름을 고려한 분석
- 라인차트, 시계열 데이터 분해, 자기상관성
패턴을 데이터로 만들기 → 기존 분석 방식 적용 시도
- 날짜 요소 추출, 이전 데이터(.shift), 이동평균(.rolling), 차분(.diff)
- y의 차분 : 숫자인가? 변화량인가
차분
diff()
- 특정 시점 데이터, 이전시점 데이터와의 차이 구하기
- y에 패턴이 안 보인다면 차분 사용 고려