

728x90

데이터 수집 복습
1. Web
Server & Client Architecture
-------------------- request -------------------->
Client Internet Server
<------------------ responose --------------------
Client
- Request : Browser를 사용하여 Server에 데이터를 요청
Server
- Response : Client의 Browser에서 데이터를 요청하면 요청에 따라 데이터를 Client로 전송
URL
| http://news.naver.com:80/main/read.nhn?mode=LSD&mid=shm&sid1=105&oid=001&aid=0009847211#da_727145 |
|
| http:// | Protocol |
| News | Sub Domain |
| naver.com | Primary Domain |
| 80 | Port |
| /main/ | Path |
| read.nhn | Page ( File ) |
| mode=LSD | Query |
| #da_727145 | Fragment |
HTTP Request Methods
Get
- URL에 Query 포함
- Query(데이터) 노출, 전송 가능 데이터 작음
Post
- Body에 Query 포함
- Query(데이터) 비노출, 전송 가능 데이터 많음
Cookie, Session, Cache
Cookie
- Client의 Browser에 저장하는 문자열 데이터
- 사용예시 : 로그인 정보, 내가 봤던 상품 정보, 팝업 다시보지 않음 등
Session
- Client의 Browser와 Server의 연결 정보
- 사용예시 : 자동 로그인
Cache
- Client, Server의 RAM(메모리)에 저장하는 데이터
- RAM에 데이터를 저장하면 데이터 입출력이 빠름
Web Language & Framework
Client (Frontend)
- HTML
- CSS - Bootstrap, Semantic UI, Materialize, Material Design Lite
- Javascript - react.js, vue.js, angular, jQuery
Server (Backend)
- Python - Django, Flask, FastAPI
- Java - Spring
- Ruby - Rails
- Scala - Play
- Javascript - Express(node.js)
Scraping & Crawling
- 웹 스크래핑: 웹 페이지에서 내가 원하는 데이터를 추출하는 것.
- 웹 크롤링: 웹 페이지에서 주어진 링크들을 따라가며 모든 데이터를 추출하는 것
2. Web Crawling
웹페이지의 종류
- 정적인 페이지(static website)
- 웹 브라우져에 화면이 한번 뜨면 이벤트에 의한 화면의 변경이 없는 페이지
- 크롤링을 수행할 때 데이터를 HTML 형태로 응답
- 동적인 페이지(dynamic website)
- 웹 브라우져에 화면이 뜨고 이벤트가 발생하면 서버에서 데이터를 가져와 화면을 변경하는 페이지
- 크롤링을 수행할 때 데이터를 json 형태로 응답
- 웹 브라우져에 화면이 뜨고 이벤트가 발생하면 서버에서 데이터를 가져와 화면을 변경하는 페이지
3. 동적 페이지 실습
1. 라이브러리
import warnings
warnings.filterwarnings('ignore') # 경고문 생략
import requests
import pandas as pd
2. URL
- pc용 웹페이지에 비해 모바일 웹페이지에서 더 쉽게 url을 가져올 수 있음
- F12(개발자 도구)를 누른 뒤 아래 아이콘 클릭
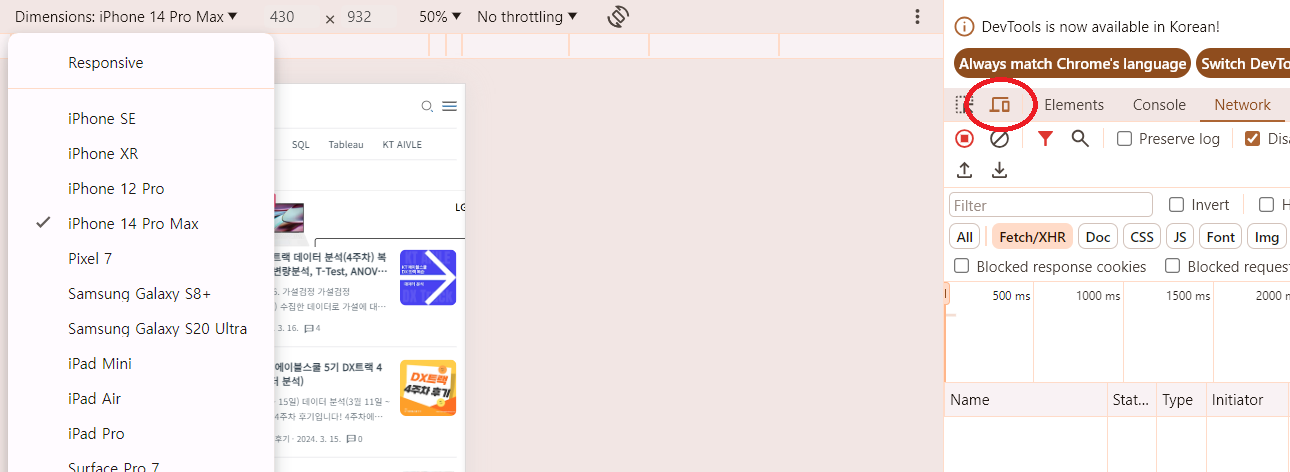
- Network - Fetch/XHR - 원하는 URL 선택
- Headers에서 Request URL, Method 확인


3. 크롤링 과정
page_size, page = 30, 1
url = f'https://주소/?pageSize={page_size}&page={page}'
# get 방식으로 response 불러오기
response = requests.get(url)
# response의 데이터를 .json() 함수를 사용해 리스트 형태로 변환
data = response.json()
# data를 데이터프레임으로 변환
df = pd.DataFrame(data)
error 날 때
response = requests.get(url)
response
# <Response [200]>
response.text[:500]- esponse의 status code가 200이 나오는지 확인
- 403이나 500이 나오면 request가 잘못되거나 web server에서 수집이 안되도록 설정이 된것임
- header 설정 또는 selenium 사용
- 200이 나오더라도 response 안에 있는 내용을 확인 > 확인하는 방법 : response.text
# headers 추가
headers = {
'User-Agent' : '__',
'Referer' : '__', # ,를 찍어주는 것이 후에 에러 처리할 때 용이
}
response = requests.get(url, headers = headers)
response
4. REST API
- Representational State Transfer
- Client와 Server가 통신하기 위한 URL 구조에 대한 정의 및 디자인
- 인코딩 디코딩 변환 사이트 https://meyerweb.com/eric/tools/dencoder/
5. HTML(Hyper Text Markup Language)
- 웹 문서를 작성하는 마크업 언어
HTML 구조
<!DOCTYPE html>
<html>
<head>
<title>문서 제목</title>
</head>
<body>
<h1>제목</h1>
<p>내용</p>
<a href="https://www.example.com">링크</a>
<img src="image.jpg" alt="이미지 설명">
</body>
</html>- <!DOCTYPE html>: 문서의 형식을 HTML로 지정하는 선언
- <html>: HTML 문서의 시작을 나타내는 요소
- <head>: 문서의 메타데이터와 외부 리소스에 대한 정보를 포함하는 요소
- <title>: 문서의 제목을 정의하는 요소
- <body>: 문서의 본문을 포함하는 요소
- <h1>, <p>, <a>, <img> 등: 각각 제목, 문단, 링크, 이미지를 나타내는 요소들
6. CSS Selector
- CSS 스타일을 적용시킬 HTML 엘리먼트를 찾기 위한 방법
Element Selector
- HTML 요소의 이름을 사용하여 해당 요소를 선택
- ex) p는 모든 <p> 요소를 선택
ID Selector
- HTML 요소의 고유한 아이디를 기반으로 요소를 선택
- 아이디 선택자는 해시(#)로 시작하며, 아이디 이름을 지정
- ex) #idname은 id="idname"을 가진 요소를 선택
Class Selector
- HTML 요소에 지정된 클래스를 기반으로 요소를 선택
- 클래스 선택자는 점(.)으로 시작하며, 클래스 이름을 지정
- ex) classname은 class="classname"을 가진 모든 요소를 선택
not Selector
- 셀렉터로 엘리먼트를 하나만 제거하고 싶을때 사용
- not을 사용하여 셀렉트 할때에는 `:not(선택에서 제거하고 싶은 셀렉터)`으로 선택
first-child Selector
- 엘리먼트로 감싸져있는 가장 처음 엘리먼트가 설정한 셀렉터와 일치하면 선택
- `.ds:first-child`로 설정하면 ds1과 ds3가 선택
last-child Selector
- 엘리먼트로 감싸져있는 가장 마지막 엘리먼트가 설정한 셀렉터와 일치하면 선택
- `.ds:last-child`로 `div.ds`가 선택되어 ds3~ds7이 선택
nth-child Selector
- 엘리먼트로 감싸져있는 n번째 엘리먼트가 설정한 셀렉터와 일치하면 선택
- `.ds:nth-child(3), .ds:nth-child(4)`로 설정하면 ds4, ds5가 선택
7. 정적 페이지 실습
1. 라이브러리
import pandas as pd
import requests
from bs4 import BeautifulSoup
2. 크롤링 과정
url = 'https://www.gmarket.co.kr/n/best'
response = requests.get(url)
# BeautifulSoup
dom = BeautifulSoup(response.text, 'html.parser')
type(dom) # bs4.BeautifulSoup
# 200개 상품 선택: select()
elements = dom.select('#gBestWrap > div.best-list > ul > li')
len(elements), elements[0] #
# 1개의 상품에서 데이터 추출: select_one()
element = elements[0]
data = {
'title': element.select_one('.itemname').text,
'img': 'http:' + element.select_one('img.image__lazy').get('src'),
'price': element.select_one('.s-price').text,
}
bs > DataFrame
items = []
for element in elements:
data = {
'title': element.select_one('.itemname').text,
'img': 'http:' + element.select_one('img.image__lazy').get('src'),
'price': element.select_one('.s-price').text,
}
items.append(data)
df = pd.DataFrame(items)
download image
link = df.loc[0, 'img']
response = requests.get(link)
with open('data.png', 'wb') as file:
file.write(response.content)
# pillow : 이미지 전처리 패키지
from PIL import Image as pil
pil.open('data.png')
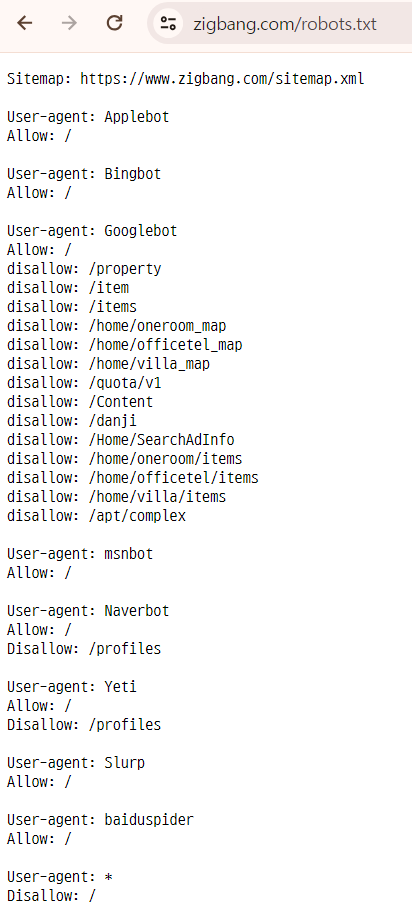
8. 크롤링 정책
robots.txt
- 크롤링 정책을 설명한 페이지
- 지적재산권, 서비스과부하(업무방해, 피해보상), 데이터사용표
- ex) 직방/robots.txt
728x90